من الصعب على نماذج التعرف التلقائي على الكلام ASR فهم أحكام التجويد بدقة. فهي لا تقاس على مستوى الكلمات بل على مستوى الحرف وصفته ومدّه وغنّته، وهي تفاصيل لا تلتقطها هذه النماذج عادة.
يعمل مشروع المعلم القرآني Quran Muaalem الذي طوّره عبدالله عبدالفتاح بالتعاون مع محمد خليل وحازم عباس على تجاوز هذا القصور بتوفير نموذج صوتي بنهج مبتكر يفهم التجويد على مستوى الحرف والصفة باستخدام أحدث تقنيات الذكاء الاصطناعي والتعلم العميق، ويوفر نظامًا متكاملًا لاكتشاف وتصحيح أخطاء النطق في التلاوة.
ما الذي يميز المعلم القرآني؟
يمثل مشروع Quran Muaalem نقلة نوعية في نماذج التعرف الصوتي، فهو ليس مجرد نموذج ASR تقليدي لتحويل الكلام المنطوق لنص مكتوب، بل نموذجًا مصممًا خصيصًا لتقييم التلاوة عن طريق تطوير رسم صوتي للقرآن الكريم يصف كل قواعد التجويد وصفات الحروف.
يعتمد النموذج على تحليل التلاوة عبر ثلاثة مستويات مترابطة:
- الفونيم: صحة نطق الحرف
- الصفة الصوتية: مطابقة صفة الحرف (همس، جهر، شدة…)
- حكم التجويد: تطبيق أحكام التجويد كالمد والغنة
كيف يفهم النموذج التلاوة؟
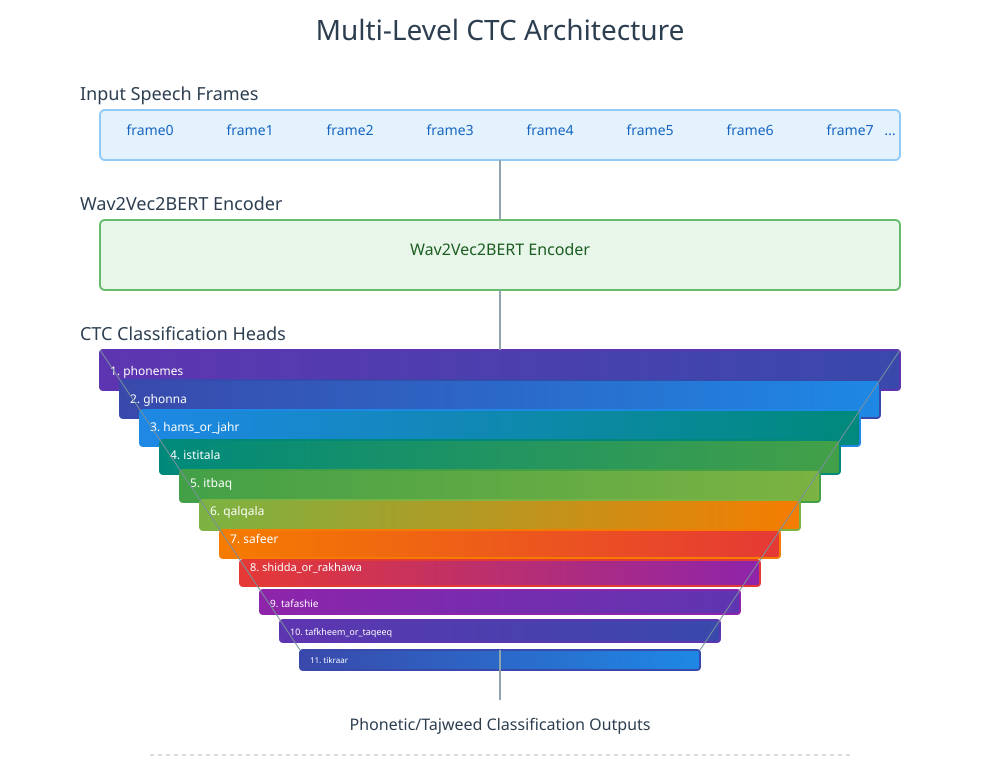
إدخال الصوت كوحدات Frames
يقسم الصوت إلى وحدات صغيرة جدًا تسمح بالتقاط متغيرات دقيقة مثل بداية الغنة ونهايتها وطول المد ونطق القلقلة.
تحويل الصوت إلى تمثيل رقمي باستخدام Wav2Vec2-BERT
يتولى مُشفّر Encoder تحويل الصوت الخام لتمثيل رقمي يلتقط السمات الصوتية الدقيقة كالتردد، والطاقة، ودرجة الهواء الخارج، والفروق بين الحروف المتقاربة.
ويعتمد في ذلك على نموذج Wav2Vec2-BERT المُدرَّب على ملايين الساعات الصوتية ويملك قدرة عالية على فهم نطق الحروف وصفاتها بدقة كبيرة.
طبقات متعددة المستويات Multi-Level CTC
في نماذج ASR العادية، ينتج النموذج سلسلة واحدة فقط وهي النص الذي سمعه. أما في Quran Muaalem فالأمر مختلف حيث يعتمد النموذج على بنية Multi-Level CTC تنتج 11 سلسلة صوتية، كل سلسلة متخصصة في جانب تجويدي مختلف.
| رقم السلسلة | المعلومة | ما الذي تلتقطه السلسلة؟ |
|---|
| 1 | الفونيم Phoneme | تحديد الحرف الذي نُطق فعليًا |
| 2 | الحركة | فتح، كسر، ضم، سكون، تشديد |
| 3 | المد | مقدار المد الطبيعي ومد البدل |
| 4 | الغنة | قوة الغنة ومدتها وموضعها |
| 5 | القلقلة | مدى تحقيق القلقلة |
| 6 | التفخيم والترقيق | هل الحرف مفخم أم مرقق؟ |
| 7 | الهمس والجهر | انتقال الهواء والصوت أثناء النطق |
| 8 | الشدة والرخاوة | درجة انحباس الصوت أو انسيابه |
| 9 | الإطباق والانفتاح | التصاق اللسان بالحنك أو انفصاله |
| 10 | الاستعلاء والاستفال | ارتفاع اللسان أو انخفاضه أثناء النطق |
| 11 | صفات إضافية | صفات مكملة تستخدم أثناء المحاذاة الصوتية الدقيقة |
هذه البنية تمكّن النموذج من فصل الأخطاء الصوتية الدقيقة عن الأخطاء التجويدية، وفهم الفروق التي لا تكشفها الكتابة الإملائية أو العثمانية.
المقارنة بين النطق المرجعي والنطق الفعلي
ينتج النموذج سلسلتين لكل مقطع صوتي:
- الرسم الصوتي المرجعي Reference QPS: التمثيل الصوتي الصحيح المبني على الرسم العثماني وأحكام التجويد.
- الرسم الصوتي المتوقع Predicted QPS: التمثيل الصوتي المعتمد على ما استخرجه النموذج من تلاوة المستخدم.
يتم محاذاة أو مقارنة السلسلتين Alignment وكشف الفروقات بينهما (ترقيق في موضع تفخيم، خطأ في مخرج حرف، نطق حرف بصفة غير صحيحة) وأي اختلاف يعتبر خطأً تجويديًا.
بحسب الورقة البحثية التي أعدها فريق المشروع، فقد حقق النموذج نسبة خطأ تساوي 0.16 بالمئة فقط، وهي نسبة خطأ قليلة بالنسبة للنماذج الصوتية العربية.
خط أنابيب لإنتاج بيانات قرآنية صوتية
لاتكمن ميزة المشروع في النموذج الذي يوفره فقط، بل في خط الأنابيب الذي ينتج بيانات قرآنية عالية الجودة معدة لتدريب النموذج على الرسم الصوتي للقرآن الكريم وفق المراحل التالية:
جمع التلاوات: تم جمع آلاف التلاوات برواية حفص عن عاصم من 22 قارئ، بلغ مجموع الساعات: 893 ساعة صوتية عالية الجودة
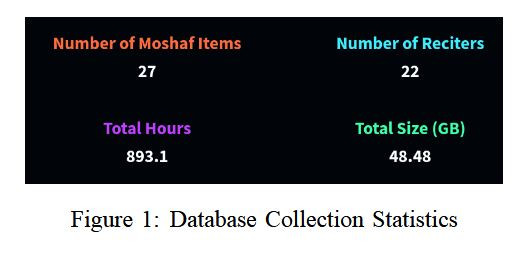
التقطيع الذكي Segmentation: لضمان أن كل مقطع قصير ومناسب للتدريب تم تطوير Segmenter خاص باستخدام Wav2Vec2-BERT يحدد مواضع الوقف والابتداء بدقة عالية بلغت 0.994
استخراج النصوص: تم الاعتماد على نموذج ترتيل Tarteel AI لاستخراج النصوص. مع تقطيع المقاطع الطويلة لوحدات أقل من 30 ثانية لأن نماذج ASR تعمل بدقة أعلى على المقاطع القصيرة.
خوارزمية التسميع: تم ابتكار خوارزمية تسميع تتحقق آليًا من تطابق كل مقطع صوتي مع نصه الصحيح، وتكشف المقاطع الناقصة أو منخفضة الجودة التي لا تصلح للتدريب وتستبعد المقاطع غير الصالحة نهائيًا (بالنتيجة: تم الحصول على 300,000 مقطع صوتي صالح للتدريب)
التحويل إلى ترميز QPS: أخيرًا تم تحويل المقاطع الصوتية عبر مكتبة quran-transcript إلى سلسلة QPS تتضمن الحرف، والحركة، والصفة، وقاعدة التجويد.. وبهذا التحويل أصبحت المقاطع مكتوبة بصيغة يمكن للنموذج مقارنتها بالنطق الفعلي مباشرة، فأي اختلاف بين Predicted QPS و Reference QPS يعد خطأ.
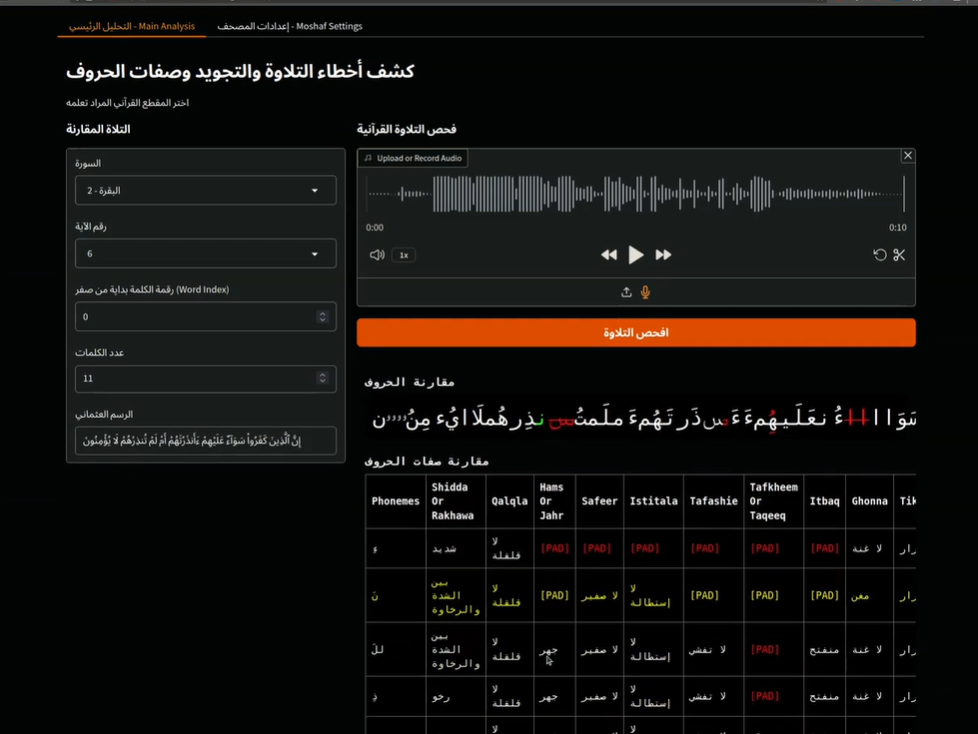
لاحظ في الصورة التالية واجهة التطبيق الذي طوره الفريق بالاعتماد على النموذج Quran Muaalem حيث تظهر:
- موجة الصوت المسجّل للآية الكريمة: "إِنَّ الَّذِينَ كَفَرُوا سَواءٌ عَلَيْهِمْ أَأَنْذَرْتَهُمْ أَمْ لَمْ تُنْذِرْهُمْ لَا يُؤْمِنُونَ"
- بجانبها سلسلة QPS التي تمثل الآية برسم صوتي دقيق كما نظقها المستخدم
- كما يظهر جدول الصفات أحكام التجويد لكل حرف، ويوضح نتيجة مقارنة النطق الفعلي بالنطق الصحيح والأخطاء المرتكبة بدقة ووضوح
روابط مفيدة
للاستزادة يمكن العودة للروابط التالية حول المشروع:
إذا كنت مطوّرًا أو باحثًا مهتمًا بخدمة القرآن الكريم، فالمشروع Quran Muaalem متاح بالكامل ويمكنك تجربته، والمساهمة في تحسينه، وتطوير تطبيقات وأدوات ذكية لتعليم التلاوة بالاعتماد عليه.