من ذكريات الطفولة إلى تحدٍّ تقني حقيقي
في الطفولة، كنت أتململ من واجب مساعدة جدتي في تلاوة القرآن الكريم، حيث كان واجبًا أسبوعيًا يوم الجمعة مساعدة جدتي في قراءة سورة الكهف. استمر هذا الحال حتى ظهر في السوق "المصحف الذكي" الذي كان يأتي مع قلم ذكي يمكنه تلاوة الآيات عند الإشارة إليها بالقلم على المصحف.

تساءلت وقتها: كيف يمكن مزامنة التلاوة الصوتية بالآية بهذه الدقة؟ كان السؤال يدور في ذهني ولم أجد له إجابة حينها. لكن اليوم، بعد سنوات، اكتشفت حجم التحدي التقني الهائل وراء ذلك المنتج البسيط ظاهريًا.
التحدي: عمل يدوي يستغرق شهورًا من الجهد المتواصل
في عملية مزامنة التلاوات الصوتية بآيات القرآن الكريم، العمل اليدوي يطغى بشكل كبير على التقنية والأتمتة. وبشهادة أحد العاملين على تطبيق سورة، فإن مزامنة المصحف كاملاً يأخذ شهورًا من العمل اليدوي المتواصل.
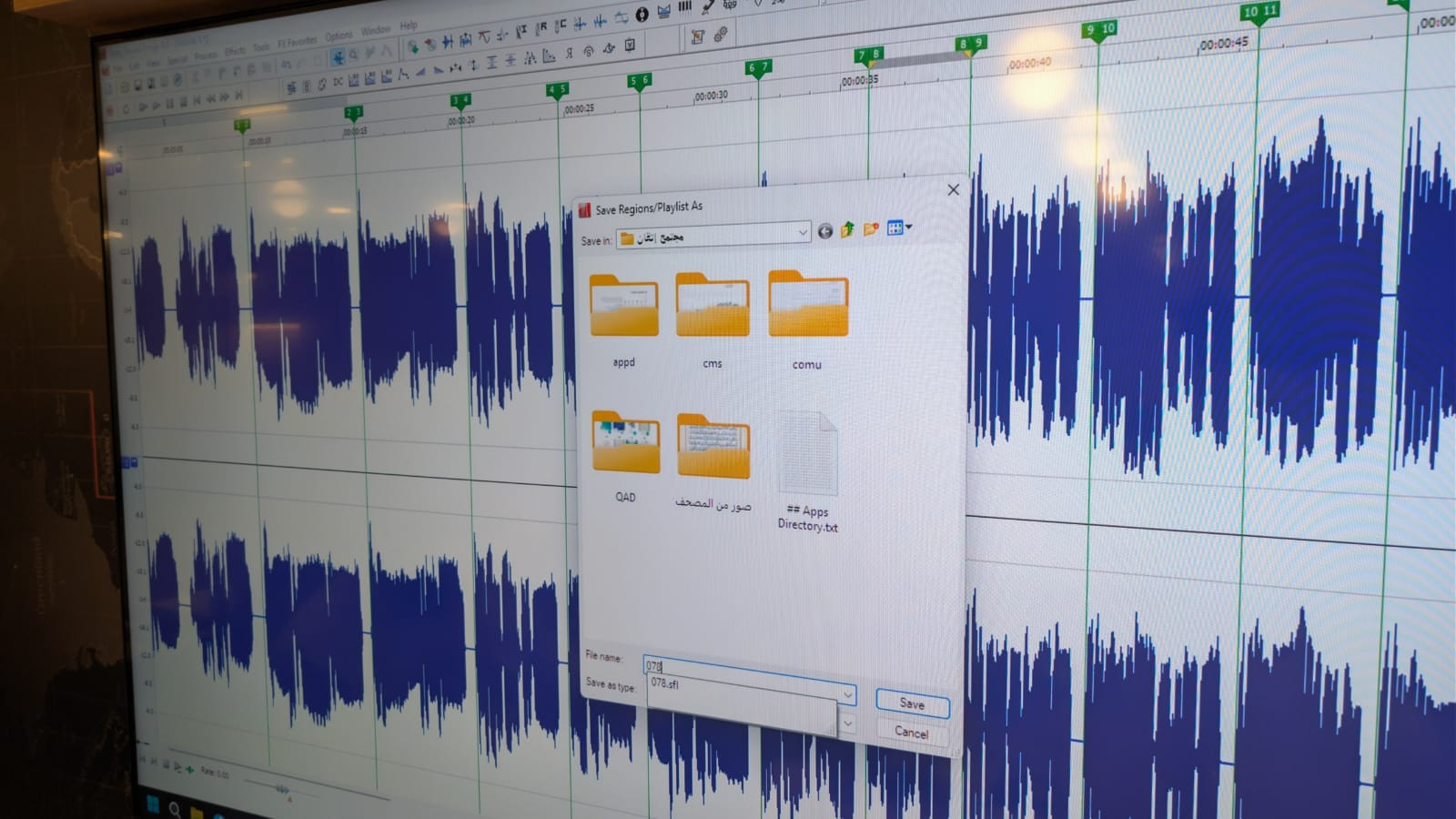
كيف تتم المزامنة اليدوية للتلاوات؟
أولا المختص في المزامنة القرآنية يفتح المقطع الصوتي في برنامج sony sound forge
وبعد ذلك بشكل يدوي يضع فواصل بين كل آية وآية
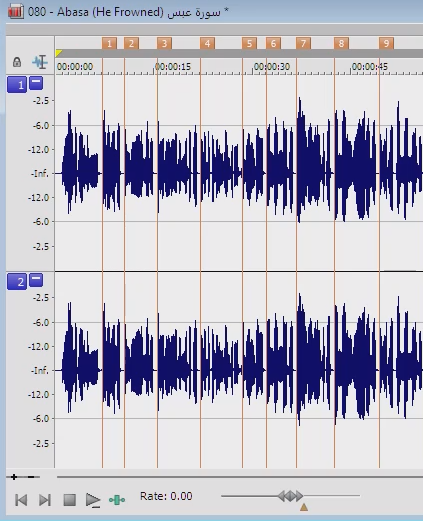
بعد هذه العملية يكون المخرج ملف نصي، فيه قائمة بالمقاطع الصوتية لكل آية في هذه السورة لهذا القارئ.
start_marker_table
00:00:09.7
00:00:15.4
00:00:20.5
00:00:24.6
00:00:27.8
00:00:32.1
00:00:35.8
00:00:38.8
00:00:42.4
00:00:46.3
00:00:49.7
00:00:54.0
end_marker_table
AUTHOR: AHMAD SHAMS
كما ترون في الصورة، المزامنة تأخذ وقتًا طويلاً وجهدًا كبيرًا. هذا التحدي يعيق:
- إضافة قراء جدد للتطبيقات القرآنية بسرعة
- دعم القراءات العشر المختلفة بكفاءة
- معالجة التسجيلات بجودات صوتية متفاوتة
- توفير الوقت والجهد الهائل على المطورين والمؤسسات
- توحيد معايير المزامنة عبر مختلف التطبيقات
لماذا هذه المشكلة مهمة ؟
التطبيقات القرآنية تحتاج إلى تلاوات مزامنة بدقة لتوفير دعم القراء للمستخدمين. لكن عملية المزامنة اليدوية تشكل عائقًا كبيرًا أمام:
- المطورين الذين يريدون إضافة قراء متعددين بسرعة
- المؤسسات التي تمتلك أرشيفات ضخمة من التلاوات الخامة الغير مزمنة
من منطلق هذه التحديات، بدأ أحمد شمس وعمر حمدي العمل على مشروع منجّم أداة مفتوحة المصدر لأتمتة تقطيع ومزامنة التلاوات القرآنية زمنيًا مع نص المصحف، وانضممت لهم لاحقا في قيادة تطوير المشروع.
رؤية المشروع
وجود آلية موحدة تقبل جميع التلاوات المسجلة بجودات مختلفة وبالقراءات كلها، ومزامنتها بآيات القرآن الكريم بشكل دقيق وسريع، مما يوفر:
- للمطورين: واجهة برمجية موحدة لمزامنة أي تلاوة
- للمؤسسات: حل سريع لمزامنة أرشيفات التلاوات الضخمة
- لمجتمع اتقان: بنية تحتية مفتوحة المصدر تدعم الابتكار في التطبيقات القرآنية والمحتوى الصوتي
كيف يعمل منجّم؟ مثال عملي من سورة الملك
لنأخذ سورة الملك كمثال عملي لفهم كيفية عمل منجّم:
الخطوة الأولى: تحميل التلاوة
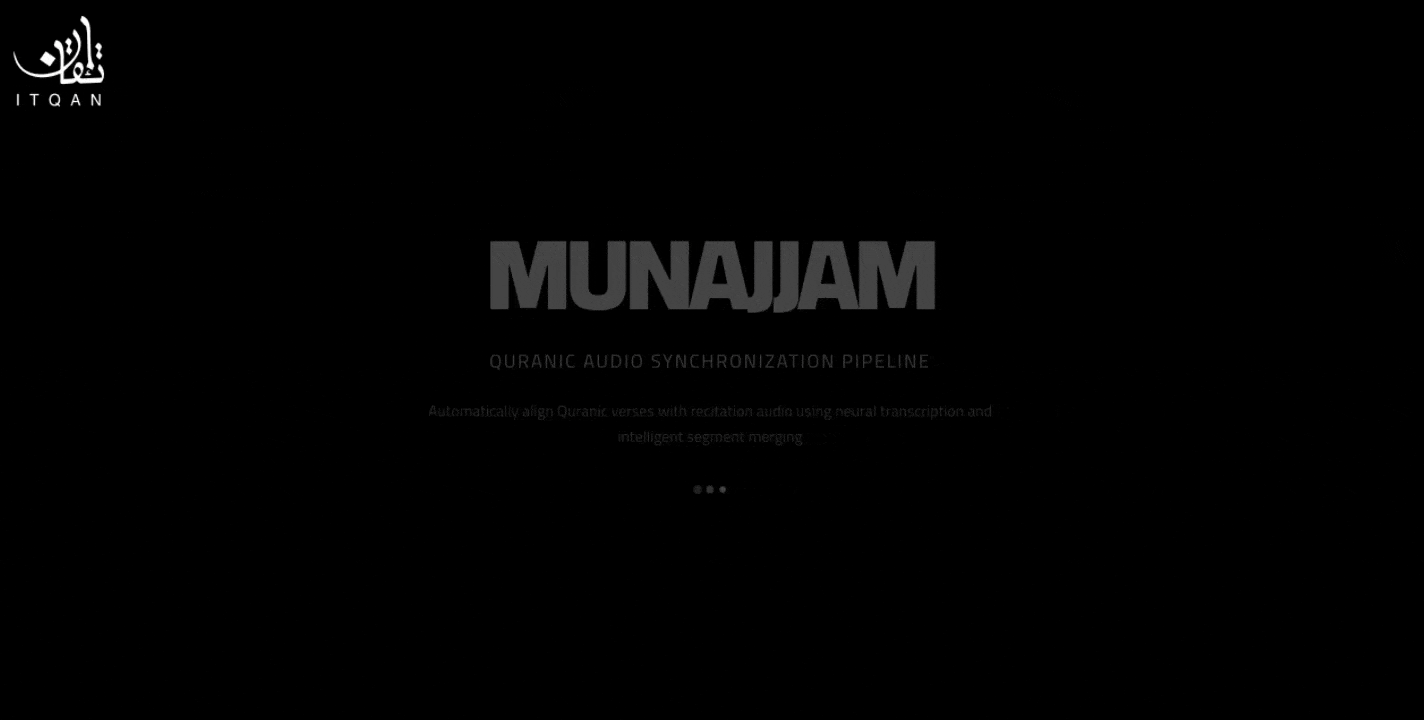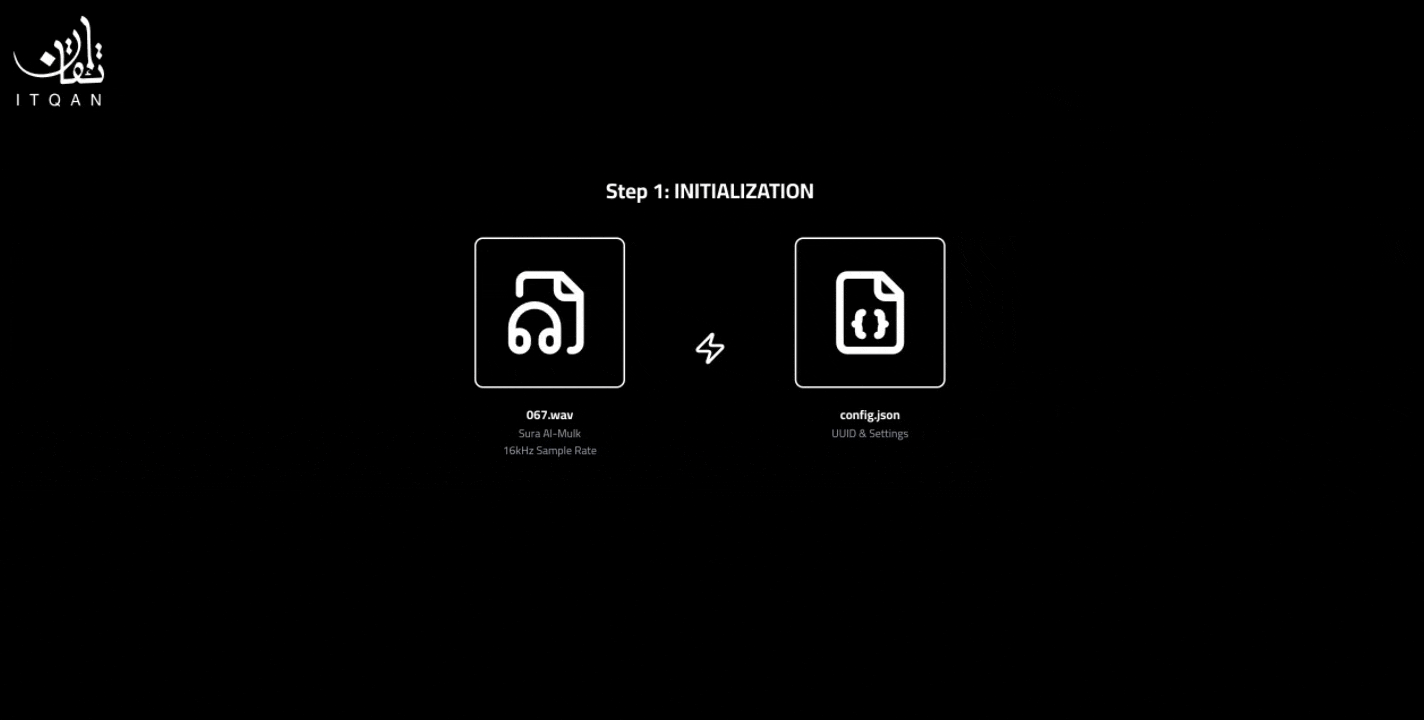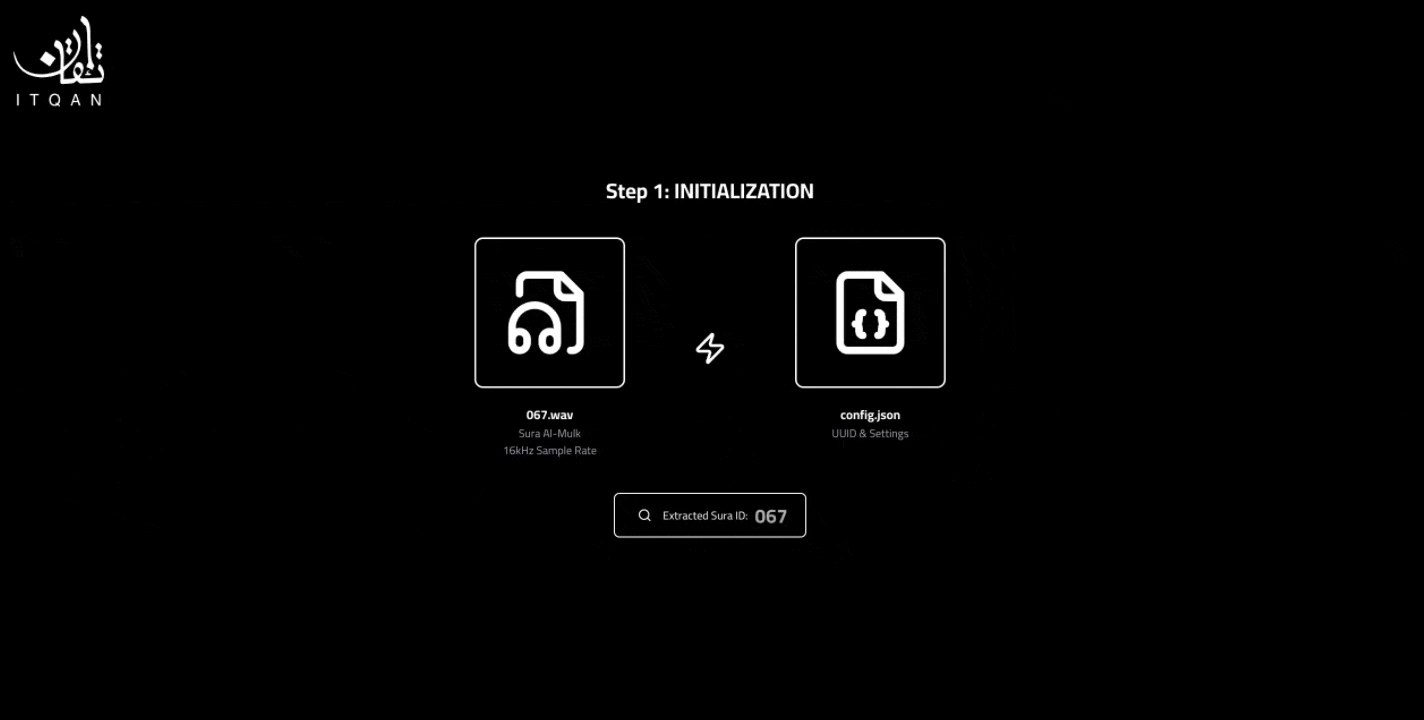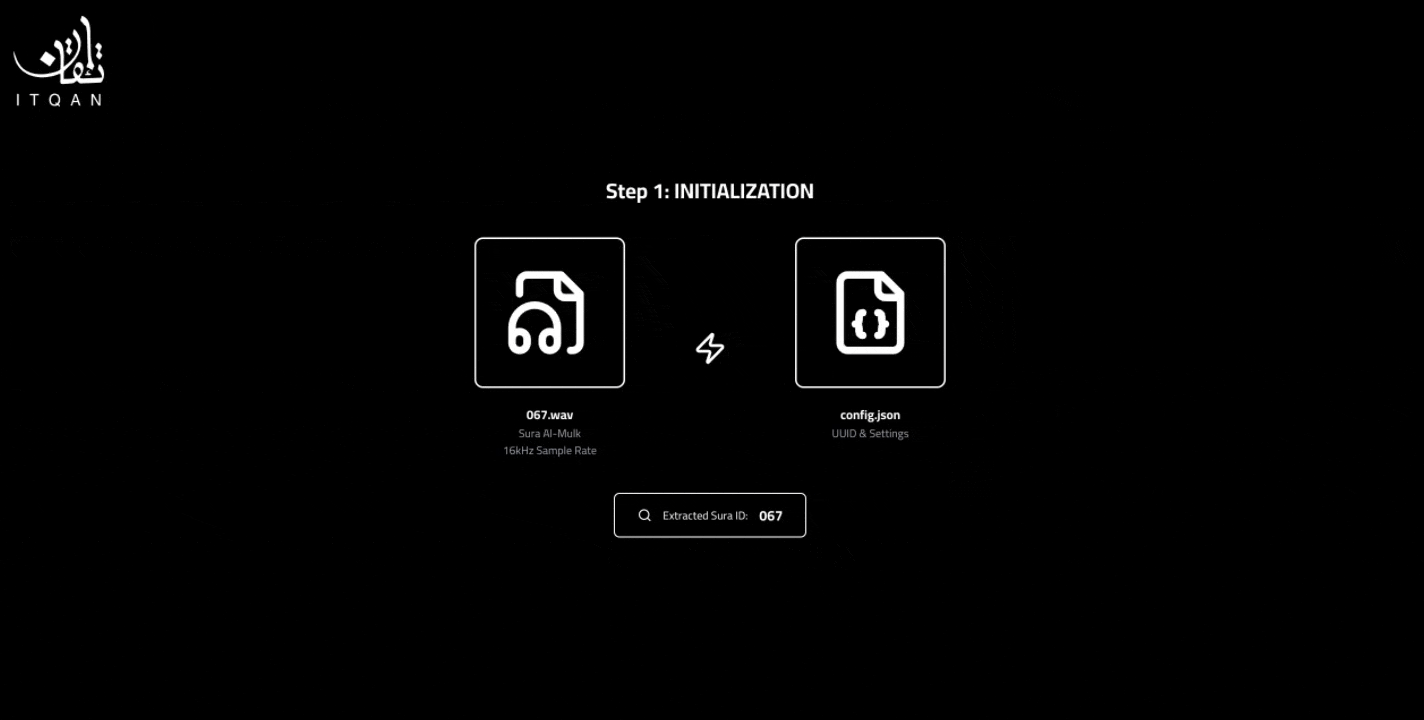
وجود التلاوة بصيغة wav (حالياً منجّم يدعم التلاوات بقراءة حفص فقط).
الخطوة الثانية: اكتشاف السكتات واستخراج المقاطع الصوتية

في هذه الخطوة يقوم منجّم باستخدام مكتبة pydub باكتشاف السكتات وفق المعايير التالية:
- السكتة: أقل من
30dB
- الحد الأدنى لمدة السكتة:
300ms
بناءً على هذه السكتات، يتم استخراج مقاطع صوتية. ملاحظة مهمة: هذه المقاطع لا تمثل الآيات بالضرورة، بل هي مقاطع صوتية مقطّعة بناءً على السكتات فقط، فربما يسكت القارئ في منتصف الآية.
الخطوة الثالثة والرابعة: تحويل المقاطع الصوتية إلى نصوص


والآن باستخدام نموذج tarteel-ai/whisper-base-ar-quran من تطوير فريق tarteel يتم معالجة جميع المقاطع الصوتية وتحويلها إلى نصوص.
في هذه المرحلة أيضاً، يتم اكتشاف الاستعاذة والبسملة تلقائياً باستخدام أنماط regex:
# اكتشاف الاستعاذة
isti3aza_pattern = re.compile(r"اعوذ بالله من الشيطان الرجيم")
# اكتشاف البسملة
basmala_pattern = re.compile(r"(?:ب\\s*س?م?\\s*)?الله\\s*الرحمن\\s*الرحيم")
المخرج هنا يكون على هذا الشكل، قائمة بكل المقاطع الصوتية:
[
{
"id": 0,
"sura_id": 67,
"surah_uuid": "4d196baf-c0bf-4ca4-b0fc-3f4a89981345",
"start": 0.54,
"end": 4.86,
"text": "وَعُوذُ بِاللَّهِ مِنَ الشَّيْطَانِ الرَّجِيمِ",
"type": "isti3aza"
},
{
"id": 0,
"sura_id": 67,
"surah_uuid": "4d196baf-c0bf-4ca4-b0fc-3f4a89981345",
"start": 6.1,
"end": 9.69,
"text": "بِاللَّهِ الرَّحْمَنِ الرَّحِيمِ",
"type": "basmala"
},
{
"id": 3,
"sura_id": 67,
"surah_uuid": "4d196baf-c0bf-4ca4-b0fc-3f4a89981345",
"start": 10.96,
"end": 18.77,
"text": "تَبَارَكَ الَّذِي بِيَدِهِ الْمُلْكُ وَهُوَ عَلَى كُلِّ شَيْءٍ قَدِيرٌ",
"type": "ayah"
}
]
الخطوة الخامسة: محاذاة المقاطع مع الآيات الفعلية

هذه هي الخطوة الأهم في منجّم، وتتضمن عدة عمليات متكاملة:
أ. تبسيط النصوص (Normalization)
قبل المقارنة، يتم تبسيط النصوص لضمان المطابقة الصحيحة:
def normalize_arabic(text):
text = re.sub(r"[أإآا]", "ا", text) # توحيد أشكال الألف
text = re.sub(r"ى", "ي", text) # توحيد الياء
text = re.sub(r"ة", "ه", text) # توحيد التاء المربوطة
text = re.sub(r"[^\\w\\s]", "", text) # إزالة علامات الترقيم
text = re.sub(r"\\s+", " ", text).strip() # إزالة المسافات الزائدة
return text
ب. خوارزمية المحاذاة
يتم مقارنة المقاطع الصوتية المُحوَّلة لنصوص مع الآيات الصحيحة ( بإمكانك الحصول على محتوى قرآني موثوق عن طريق نظام CMS من إتقان ! )، باستخدام عدة تقنيات:
1. مقارنة التشابه باستخدام SequenceMatcher:
from difflib import SequenceMatcher
def similarity(a, b):
return SequenceMatcher(None, a, b).ratio()
2. تقنية الكلمات الأخيرة: للتأكد من وصول المقطع لنهاية الآية، يتم مقارنة آخر 1-3 كلمات من المقطع مع آخر كلمات الآية الصحيحة.
3. نسبة التغطية (Coverage Ratio): يتم التحقق من أن المقطع يغطي على الأقل 70% من كلمات الآية قبل اعتباره مكتملاً.
ج. دمج المقاطع وإزالة التداخل
إذا لم يكمل المقطع الآية بأكملها، يتم دمجه مع المقطع التالي مع إزالة الكلمات المكررة:
- يدمج المقاطع بذكاء مع إزالة الكلمات المكررة
- يحافظ على سلاسة النص النهائي
- يضمن عدم تكرار أي كلمة في المخرجات
د. نظام Buffer الذكي
أثناء المحاذاة، يتم تطبيق نظام Buffer لضمان التقاط التلاوة كاملة وعدم قطع نطق الحرف الأول أو الأخير:
- يمتد للخلف حتى 0.3 ثانية في فترة الصمت السابقة
- يمتد للأمام حتى 0.3 ثانية في فترة الصمت التالية
- يمنع التداخل مع الآيات المجاورة
هـ. اكتشاف حدود الآيات
يتم استخدام الصمت (minimum 180ms) مع المقارنة النصية لاكتشاف نهاية الآيات.
الخطوة السادسة: حفظ النتائج

المخرج النهائي يحتوي على:
- النص المُستَخرج من التلاوة (transcribed_text)
- النص الصحيح من المصحف (corrected_text)
- التوقيت الدقيق لبداية ونهاية كل آية
[
{
"id": 1,
"sura_id": 67,
"ayah_index": 0,
"start": 10.66,
"end": 19.07,
"transcribed_text": "تَبَارَكَ الَّذِي بِيَدِهِ الْمُلْكُ وَهُوَ عَلَى كُلِّ شَيْءٍ قَدِيرٌ",
"corrected_text": "تَبَٰرَكَ ٱلَّذِي بِيَدِهِ ٱلۡمُلۡكُ وَهُوَ عَلَىٰ كُلِّ شَيۡءٖ قَدِيرٌ",
"uuid": "4d196baf-c0bf-4ca4-b0fc-3f4a89981345"
},
{
"id": 2,
"sura_id": 67,
"ayah_index": 1,
"start": 19.25,
"end": 30.77,
"transcribed_text": "الَّذِي خَلَقَ الْمَوْتَ وَالْحَيَاةَ لِيَبْلُوَكُمْ أَيُّكُمْ أَحْسَنُ عَمَلًا وَهُوَ الْعَزِيزُ الْغَفُورُ",
"corrected_text": "ٱلَّذِي خَلَقَ ٱلۡمَوۡتَ وَٱلۡحَيَوٰةَ لِيَبۡلُوَكُمۡ أَيُّكُمۡ أَحۡسَنُ عَمَلٗاۚ وَهُوَ ٱلۡعَزِيزُ ٱلۡغَفُورُ",
"uuid": "4d196baf-c0bf-4ca4-b0fc-3f4a89981345"
}
]
يتم حفظ النتائج في:
- ملفات JSON للمشاركة مع المطورين
- قاعدة بيانات SQLite للاستخدام المباشر
وبذلك بإمكانك دعم أي تلاوة من أي شيخ في تطبيقات القرآن الكريم.
القيم المستخدمة
| المعيار | القيمة | الوصف |
|---|
| الصمت | -30dB | الحد الأقصى لشدة الصوت لاعتباره صمتاً |
| الحد الأدنى للسكتة | 300ms | أقل مدة للسكتة لتقطيع المقاطع |
| تشابه الكلمات الأخيرة | ≥ 60% | لاكتشاف نهاية الآية |
| نسبة التغطية | ≥ 70% | للتأكد من اكتمال الآية |
| Buffer | 0.3s | التمديد في فترات الصمت |
| فجوة الصمت | ≥ 180ms | لاكتشاف حدود الآيات |
النتائج الحالية
الاختبار على القرآن الكريم كاملاً
تم اختبار خوارزمية منجّم على القرآن الكريم كاملاً (114 سورة، 6,236 آية) للقارئ بدر التركي، والنتائج كانت مُبشِّرة:
واجهنا مشاكل في السور التالية ويتم معالجتها
- البقرة
- النمل
- فاطر
- الشورى
- المدثر
- الماعون
مؤشرات الأداء:
- السور المكتملة : جميعها
- متوسط دقة المطابقة : 95%+ في معظم السور
- وقت المعالجة : 50 دقيقة للقرآن كاملاً ( Macbook Pro M2 16GB )
ما تم تحقيقه:
✅ نسخ نصي دقيق للتلاوة بأكملها
✅ تحديد حدود الآيات بدقة عالية في 108 سورة
✅ مزامنة الأوقات الزمنية بشكل صحيح
✅ معالجة الاستعاذة والبسملة بشكل منفصل
✅ إنتاج ملفات JSON جاهزة للاستخدام
التحديات المتبقية:
⚠️ بعض السور الطويلة تحتاج تحسين (البقرة: 77%، النمل: 32%)
⚠️ العمل جارٍ على تحسين خوارزمية المحاذاة للآيات المتشابهة
أ. مكتبة Python
نعمل على تحويل منجّم إلى مكتبة Python سهلة الاستخدام:
from munajjam.transcription import WhisperTranscriber
from munajjam.transcription.silence import detect_silences
from munajjam.core import align_segments
from munajjam.data import load_surah_ayahs, get_surah_name
import json
transcriber = WhisperTranscriber(
model_id="tarteel-ai/whisper-base-ar-quran",
model_type="transformers"
)
transcriber.load()
silences = detect_silences("surah_001.wav")
segments = transcriber.transcribe("surah_001.wav")
ayahs = load_surah_ayahs(1)
results = align_segments(segments, ayahs, silences_ms=silences)
for result in results:
print(f"الآية {result.ayah.ayah_number}: {result.start_time:.2f}s - {result.end_time:.2f}s")
output = {
"surah_id": 1,
"surah_name": get_surah_name(1),
"ayahs": [
{
"ayah_number": r.ayah.ayah_number,
"start": r.start_time,
"end": r.end_time,
"text": r.ayah.text,
"similarity": round(r.similarity_score, 3)
}
for r in results
]
}
with open("output.json", "w", encoding="utf-8") as f:
json.dump(output, f, ensure_ascii=False, indent=2)
transcriber.unload()
ما نحتاجه من المجتمع
نحن في بداية رحلة طويلة، ونحتاج دعمكم في عدة جوانب:
1. المساهمة التقنية
للمطورين:
- تطوير منجم ك python library
- تطوير بنية تحتيه لدعم تشغيل النماذج عن طريق (huggingFace) بدل التشغيل المحلي
- كتابة الاختبارات (Unit Tests)
- تحسين الأداء والسرعة
- إصلاح الأخطاء (Bug Fixes)
للباحثين:
- اقتراح خوارزميات أفضل
- تحسين نماذج التعلم الآلي
2. الاختبار والتجريب
نحتاج منكم:
- تجربة منجّم على تلاوات مختلفة
- الإبلاغ عن الأخطاء والمشاكل
- اقتراح تحسينات
- مشاركة حالات الاستخدام
- تقييم جودة المخرجات
التحديات التي نواجهها
من المهم أن نكون صادقين حول التحديات الحالية:
1. التحديات التقنية
- اختلافات القراءات: بعض القراءات تحتاج معالجة خاصة
- الأصوات الخلفية: تؤثر على دقة النسخ
2. التحديات البحثية
- نماذج مُحسَّنة: نحتاج نماذج أفضل للعربية القرآنية
- قياس الدقة: تطوير معايير لقياس جودة المزامنة
- البيانات التدريبية: جمع بيانات كافية للتحسين
كيف أبدأ ؟
مشروع منجّم ليس مجرد أداة تقنية، بل هو مساهمة في خدمة كتاب الله وتسهيل الوصول إليه لملايين المسلمين حول العالم. كل سطر كود نكتبه، وكل خوارزمية نطورها، وكل اختبار نجريه هو خطوة نحو تحقيق رؤية منجم.