تلاوة القرآن الكريم عبادة عظيمة، تتطلب دقة في النطق ومراعاة للتشكيل وأحكام التجويد. ومع التطورات في الذكاء الاصطناعي وتوفير نماذج التعرف على الصوت، أصبح بالإمكان إنشاء تطبيقات مساعدة تتعرف على نصوص التلاوة وتختبر دقة نطق القرّاء.
سأختبر عمليًا نموذج Whisper مدرَّب للتعامل مع مجموعات بيانات صوتية للتلاوات القرآنية. وأوضح خطوات العمل بالتفصيل بدايةً من سبب اختيار النموذج المدرب مرورًا بخطوات استخدامه في تطبيق مخصص لتقييم تلاوة الجزء الثلاثين "جزء عمَّ"، وانتهاءً بتوفير الكود البرمجي للتطبيق مع مقترحات للتحسين والتطوير.
لماذا اخترت نموذج Whisper؟
يعدّ نموذج Whisper من OpenAI أحد أقوى نماذج التعرّف الآلي على الكلام Automatic Speech Recognition أو ASR اختصارًا وهو نموذج متعدد اللغات فقد جرى تدريبه على أكثر من 680 ألف ساعة من البيانات الصوتية العامة بمختلف اللهجات واللغات من بينها اللغة العربية، وأظهر قدرةً فائقةً على تحويل الكلام المنطوق إلى نص مكتوب.
يتوفر نموذج Whisper بعدة إصدارات تختلف في الحجم والقدرة:
- whisper-small: نسخة خفيفة وسريعة، مناسبة للتطبيقات التي تتطلب سرعة استجابة مع موارد محدودة.
- whisper-base: نسخة متوسطة توازن بين السرعة والدقة، وهي خيار شائع مناسب لمعظم الاستخدامات العملية.
- whisper-large: النسخة الأكبر والأكثر قوة، توفر أفضل أداء ممكن من حيث الدقة لكنها تحتاج إلى موارد حاسوبية كبيرة.
ورغم قوة النموذج في التعرف الصوتي على الكلام، إلا أن تعرفه على التلاوة القرآنية تشكّل تحديًا خاصًا، إذ تختلف تلاوتنا للقرآن الكريم عن كلامنا العادي من حيث التشكيل، ومخارج الحروف، وأحكام التجويد. لذلك فإن أداء النموذج العام قد لا يكون مثاليًا في هذا السياق، مما يجعل عملية ضبطه Fine-Tuning على بيانات مخصصة كالتلاوات القرآنية في حالتنا خطوة أساسية لتعزيز دقته ومواءمته للاستخدام المنشود.
أهمية Fine-Tuning لنموذج Whisper
تُمكِّننا عملية Fine-Tuning -والتي تترجم إلى الصقل أو الضبط الدقيق- من تكييف نموذج ذكاء اصطناعي مدرب مسبقًا على مجموعة بيانات أصغر وأكثر تخصصًا، مثل التلاوات القرآنية في حالتنا.
فخصوصية التلاوة القرآنية كما ذكرتُ سابقًا تتطلب مراعاة التشكيل ومخارج الحروف وأحكام التجويد، وقد لا تتطابق تمامًا مع الكلام العربي العام. لذا من الضروري صقل هذه النماذج العامة لتعزيز دقة تعرفها على التلاوة.
سيوفر علينا ضبط النماذج الموارد والبيانات الهائلة التي سنحتاجها لتدريب نموذج من الصفر، والجيد أن النموذج سيحتفظ بقدرته على التعميم من البيانات العامة، كما سيكتسب تخصصًا في البيانات الجديدة.
تبدأ عملية الصقل باختيار النموذج الأساسي المناسب (whisper-base أو whisper-small أو whisper-large)، بعد ذلك تأتي مرحلة إعداد البيانات، إذ يجب مطابقة الصوت مع النصوص وتحويل الملفات إلى صيغة مناسبة يفهمها النموذج.
عند الانتهاء من التحضير، تبدأ عملية الضبط باستخدام مكتبات متخصصة مثل Hugging Face Transformers وباي تورش PyTorch فهي تمنحنا الكثير من المرونة في التعامل مع النموذج.
أخيرًا، نحتاج لتقييم العملية من خلال قياس دقة النموذج بعد ضبطه للتأكد من كفاءة التعرف على التلاوات وذلك عبر مؤشرات مثل:
- معدل الخطأ بالكلمة Word Error Rate واختصاره WER
- أو معدل الخطأ بالحرف Character Error Rat واختصاره CER
البحث عن نموذج مسبق الضبط على Hugging Face
رغم أهمية الضبط الدقيق Fine-Tuning على بيانات التلاوة القرآنية، فإنني لم أقم بضبط النموذج بنفسي، لأن عملية التدريب تحتاج إلى توفير بيانات صوتية ضخمة وموارد حاسوبية كبيرة ويصعب عليّ العمل عليها بجهد فردي.
لذلك فكرتُ في البحث عن نموذج جاهز تم ضبطه مسبقًا ومشاركته عبر منصة Hugging Face Hub. ولحسن الحظ وجدتُ عدة محاولات سابقة، وبعد مراجعة النماذج وقراءة توصيفها وقع اختياري على النموذج tarteel-ai/whisper-base-ar-quran وهو نسخة محسّنة من نموذج Whisper-base، موجهة خصيصًا للتعرف على التلاوات القرآنية باللغة العربية.
وفيما يلي أهم الأسباب التي دفعتني لاختيار tarteel-ai/whisper-base-ar-quran:
- وفرته شركة ترتيل مطورة تطبيق Tarteel AI الشهير لتلاوة القرآن وحفظه ومراجعته بالذكاء الاصطناعي
- ينتج معدل خطأ كلمات منخفض WER مقارنةً بالنماذج الأخرى.
- اعتماده من قبل عدد كبير من المشاريع أكثر من 30 Space على Hugging Face.
- توافقه مع مكتبة المحولات Transformers مما يسهّل دمجه مباشرةً في التطبيق.
بهذا وفرتُ وقتًا وجهدًا كبيرين، وانتقلتُ مباشرةً إلى مرحلة التطبيق العملي، والتي سأوضح خطواتها بالتفصيل في الفقرات التالية.
التطبيق العملي Telawa Checker
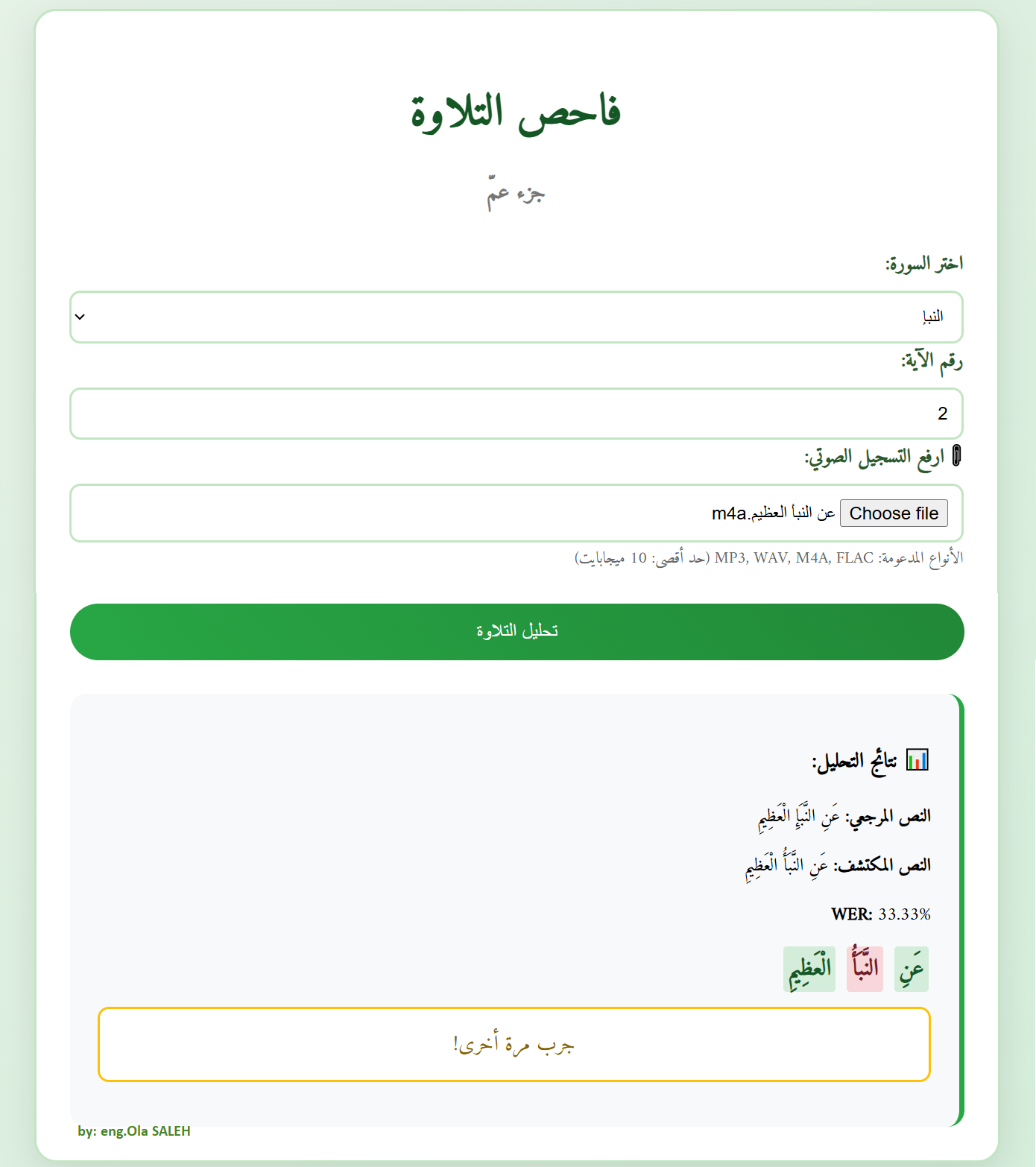
عملت على تطوير تطبيق ويب باسم فاحص التلاوة، يهدف إلى مساعدة المستخدمين على اختبار تلاوتهم للقرآن الكريم من خلال الذكاء الاصطناعي.
استخدمتُ إطار عمل فلاسك Flask في عملية التطوير لأنه مرن وصغير الحجم، ومن السهل ربطه بالواجهات البرمجية المختلفة. كما استخدمتُ الواجهة البرمجية Quran.com API لتوفير نصوص الآيات القرآنية.
يعمل التطبيق على النحو التالي: يسجّل المستخدم الآية المطلوبة ويرفعها للتطبيق، الذي يقوم أولًا بتحويل التسجيل الصوتي إلى صيغة WAV Mono 16kHz باستخدام مكتبة معالجة الصوتيات pydub وبرنامج ffmpeg.
هذه الخطوة ضرورية لضمان توافق التسجيل الصوتي مع نموذج تقييم التلاوة، إذ أن نماذج ASR لا تعمل إلا مع ملفات صوتية ذات صيغة وخصائص محددة مسبقًا. فالتسجيلات قد تصل بصيغ مختلفة مثل MP3 أو Stereo، مما قد يؤدي إلى انخفاض دقة التعرف على الكلام أو حتى إلى حدوث أخطاء في المعالجة.
بعد ذلك، يبدأ النموذج بتحويل الصوت إلى نص مكتوب ثم يقارن الكلمات الناتجة بالنص القرآني المرجعي للآية باستخدام مكتبة jiwer من خلال حساب نسبة الخطأ في الكلمات WER، ويعرض تقييم لأداء التلاوة.
ملاحظة1: يدعم التطبيق مكتبة المحولات Transformers لتشغيل النموذج بكفاءة على أجهزة GPU أو CPU، ويعرض الفروقات بين النص المكتشف والنص المرجعي للآية من خلال تلوين الكلمات الصحيحة والخاطئة والمفقودة بشكل مختلف.
ملاحظة2: اقتصرت النسخة الحالية للتطبيق على اختبار الجزء الثلاثين من القرآن الكريم (جزء عمّ) لجعل التجربة مناسبة للأطفال والمبتدئين، ولتقليل استهلاك الموارد وضمان سرعة الاستجابة.
البنية البرمجية للتطبيق
يتكون التطبيق من ملفين أساسيين، بالإضافة لبعض الملفات المساعدة:
1. ملف الواجهة الخلفية app.py
يحتوي هذا الملف على المنطق الأساسي للتطبيق، ويشمل:
تحميل نموذج التعرف على الكلام ASR
تم استخدام مكتبة المحولات Transformers من Hugging Face لتحميل نموذج Whisper المخصص للقرآن الكريم. يقوم الـ pipeline بتهيئة النموذج تلقائيًا، ويستفيد من بطاقة GPU عند توفرها لتحسين سرعة وكفاءة التعرف على الكلام.
MODEL_NAME = "tarteel-ai/whisper-base-ar-quran"
device = 0 if torch.cuda.is_available() else -1
asr_pipe = pipeline("automatic-speech-recognition", model=MODEL_NAME, device=device)
جلب نصوص القرآن الكريم
يجلب التطبيق النص المرجعي (الإملائي) للآية المطلوبة من الواجهة البرمجية Quran.com APIكما يلي:
API_BASE_URL = "https://api.quran.com/api/v4"
def get_ayah_text(surah_id, ayah_number):
url = f"{API_BASE_URL}/verses/by_key/{surah_id}:{ayah_number}?language=ar"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
return data["verse"]["text_imlaei"]
return None
معالجة النصوص
تعمل الدالة normalize_text_for_compare على تقييس أو تطبيع النصوص Normalize بإزالة علامات الترقيم والأرقام وتنظيف المسافات لتسهيل المقارنة الدقيقة بينها، مع الاحتفاظ بالتشكيل لأهميته في التلاوة.
def normalize_text_for_compare(text):
if not text:
return ""
# إزالة علامات الترقيم والأرقام
text = re.sub(
r"[^\w\s\u0600-\u06FF\u064B-\u065F\u0610-\u061A\u06D6-\u06ED]", "", text
)
text = unicodedata.normalize("NFKC", text) # تطبيع Unicode للتشكيل
return " ".join(text.split()) # تنظيف المسافات
المقارنة وتلوين النصوص
استخدمت الوحدة المدمجة في بايثون difflib.SequenceMatcher لمقارنة كلمات النص المرجعي ref_text مع النص المكتشف وتلوين الكلمات كالتالي: أخضر للكلمات صحيحة وأحمر للكلمات الخاطئة أو المستبدلة، وبرتقالي للكلمات المضافة.
def color_diff_html(ref_text, hyp_text):
matcher = SequenceMatcher(None, ref_text.split(), hyp_text.split())
html = []
for opcode, a0, a1, b0, b1 in matcher.get_opcodes():
if opcode == 'equal':
html.append(f'<span class="correct">{" ".join(ref_text.split()[a0:a1])}</span>')
elif opcode == 'replace':
html.append(f'<span class="wrong">{" ".join(hyp_text.split()[b0:b1])}</span>')
elif opcode == 'insert':
html.append(f'<span class="insert">{" ".join(hyp_text.split()[b0:b1])}</span>')
elif opcode == 'delete':
html.append(f'<span class="deleted">{" ".join(ref_text.split()[a0:a1])}</span>')
return " ".join(html)
تقييم التلاوة
تتضمن الدالة evaluate_recitation كل خطوات المعالجة من تحويل الصوت إلى التعرف على النص مرورًا بالمقارنة ثم التقييم كما يلي:
def evaluate_recitation(audio_path, surah_id, ayah_number):
# 1. تحويل الملف إلى WAV
wav_path = convert_to_wav(audio_path)
# 2. التعرف على النص
result = asr_pipe(wav_path)
hypothesis = result["text"]
# 3. جلب النص المرجعي
reference_raw = get_ayah_text(surah_id, ayah_number)
# 4. التطبيع والمقارنة
ref = normalize_text_for_compare(reference_raw)
hyp = normalize_text_for_compare(hypothesis)
# 5. حساب نسبة الخطأ
error_rate = wer(ref, hyp)
# 6. تلوين النصوص وإرجاع النتيجة
diff_html = color_diff_html(ref, hyp)
return {
"reference": reference_raw,
"hypothesis": hypothesis,
"wer": error_rate,
"diff_html": diff_html
}
المسارات Routes
يعرف الكود مسارًا رئيسيًا في Flask، حيث تعرض GETالنموذج الفارغ، بينما تستقبل POSTالسورة ورقم الآية والتسجيل الصوتي، ثم تحلل التلاوة وتعرض النتيجة.
app = Flask(__name__)
@app.route("/", methods=["GET", "POST"])
def index():
if request.method == "POST":
surah_id = request.form["surah"]
ayah_number = request.form["ayah"]
audio = request.files["audio"]
result = evaluate_recitation(audio, surah_id, ayah_number)
return render_template("index.html", result=result)
return render_template("index.html")
2. ملف الواجهة الأمامية index.html
يعرّف هذا الملف واجهة المستخدم المكوّنة من قسمين رئيسيين:
- قسم إدخال البيانات: يتيح للمستخدم اختيار السورة ورقم الآية، ثم رفع ملف التسجيل الصوتي الخاص بالآية المختارة.
- قسم عرض النتائج: يُظهر النص المرجعي (الآية الصحيحة)، والنص المستخرج من التسجيل عبر نموذج ASR، بالإضافة إلى نسبة الخطأ في الكلمات WER ونتيجة التقييم النهائية.
3. ملفات أخرى مساعدة
- requirements.txt: يضم المكتبات الأساسية اللازمة لعمل المشروع
- readme.md: يوفر معلومات عامة عن المشروع وطريقة تشغيله
الكود الكامل للتطبيق
وفرت الكود الكامل للتطبيق تحت رخصة MIT لاستخدامه وتعديله وتوزيعه مع ذكر حقوق المؤلف الأصلية.
يمكن تحميل الكود من مستودع GitHub من خلال هذا الرابط
نقاش حول التجربة والتحسينات المستقبلية
تجربتي مع هذا المشروع ليست سوى خطوة أولى لاستكشاف قدرة نموذج الذكاء الاصطناعي Whisper على فهم وتصحيح تلاوة القرآن الكريم. يمكن تحسين المشروع بطرق متعددة مثل تجربة نماذج مختلفة، أو تدريب النموذج الحالي على مجوعة بيانات لتلاوات قرآنية أشمل وأكثر تنوعًا، أو ربما تمكين النموذج من التعلم المستمر ليصبح أكثر دقة مع كل استخدام.
أرحب بتعليقاتكم وأسئلتكم حول هذه التجربة، وأود معرفة أهم الميزات التي تفضلون وجودها في تطبيقات اختبار التلاوة بالذكاء الاصطناعي، وما هي أبرز التحديات التي تتوقعون مواجهتها في هذا النوع من التطبيقات سواء من وجهة نظر مستخدمين أو مطورين لهذه التطبيقات.