المؤلف: طارق منصور
مؤسس: iPhoneIslam.com
الملخص
تقدم هذه الورقة منهجية لتمكين الذكاء الاصطناعي من البحث في القرآن الكريم بدقة، وذلك من خلال تزويده بأدوات بحث متخصصة بدلاً من تدريبه مباشرة على النص القرآني. نُجادل بأن الدور الأمثل للذكاء الاصطناعي في التعامل مع القرآن الكريم — حيث الدقة النصية أمر بالغ الأهمية — هو أن يكون محسِّناً ذكياً للاستعلامات يترجم اللغة الطبيعية إلى أوامر بحث متخصصة. يُزيل هذا النهج القائم على استدعاء الأدوات مشكلة "الهلوسة" (Hallucination) المتأصلة في الذكاء الاصطناعي التوليدي مع الحفاظ على سهولة استخدام اللغة الطبيعية. نوضح كيف يمكن لنظام ذكاء اصطناعي مُجهَّز بأدوات للتصنيف الموضوعي والتحليل الصرفي وعد الكلمات واختبار الاستعلامات أن يُنتج نتائج تتوافق مع توقعات العلماء مع الحفاظ الكامل على أمانة النص.
١. المقدمة: مشكلة الذكاء الاصطناعي مع القرآن الكريم
١.١ لماذا يتطلب القرآن معاملة خاصة
يحتل القرآن الكريم مكانة فريدة بين النصوص التي تُعالَج حاسوبياً. فنحن نؤمن بأنه كلام الله الحرفي المحفوظ — لم يتغير حرفاً عبر أربعة عشر قرناً. وهذا يضع متطلبات استثنائية على أي نظام ذكاء اصطناعي يتعامل معه:
١. عدم التسامح مطلقاً مع الخطأ النصي — حرف واحد خطئ أمر غير مقبول
٢. الدقة العلمية — يجب أن تتوافق النتائج مع ما يتوقعه العلماء المسلمون
٣. إمكانية التتبع الكاملة — كل آية يجب أن يكون لها موقع مصدر قابل للتحقق
هذه المتطلبات تجعل القرآن حالة دراسية مثالية لتطوير منهجيات الذكاء الاصطناعي للنصوص القرآنية والمتخصصة.
١.٢ المشكلة الجوهرية في تدريب الذكاء الاصطناعي على القرآن
عندما ندرب نموذج لغوي كبير (LLM) على القرآن، نواجه تناقضاً جوهرياً:
نماذج اللغة الكبيرة هي مولّدات نصوص احتمالية. تتنبأ بالرمز التالي الأكثر احتمالاً بناءً على أنماط تعلمتها أثناء التدريب. عند السؤال عن آيات قرآنية، قد يقوم النموذج المُدرَّب بـ:
- توليد نص يشبه العربية القرآنية لكنه غير موجود
- دمج أجزاء من آيات مختلفة في تركيبات مُختلَقة
- تقديم اقتباسات صحيحة تقريباً لكن مع استبدال كلمات
- نسب الآيات لمواقع خاطئة (سورة أو رقم آية خطأ)
القرآن يتطلب استرجاعاً حتمياً.** يتوقع المستخدمون الآية بالضبط، وليس تقريباً احتمالياً. لا يوجد هامش خطأ مقبول.
١.٣ أطروحتنا: الذكاء الاصطناعي يجب أن يبحث، لا أن يُولِّد
نقترح تحولاً جوهرياً في كيفية تفاعل الذكاء الاصطناعي مع القرآن:
دور الذكاء الاصطناعي يجب أن يكون تحسين الاستعلامات، وليس توليد النص.
بدلاً من تدريب الذكاء الاصطناعي على حفظ أو توليد النص القرآني، نزوده بـ أدوات بحث تتصل بفهرس موثق ومُحقَّق. تصبح مهمة الذكاء الاصطناعي:
١. فهم ما يبحث عنه المستخدم
٢. اختيار الأداة المناسبة لنوع البحث
٣. بناء استعلام مُحسَّن
٤. التحقق من أن الاستعلام يُرجع نتائج ذات معنى
٥. إرجاع النتائج المُوثَّقة من الفهرس
هذا النهج يضمن أن كل نتيجة هي استرجاع أمين من المصدر الأصلي — تصبح "الهلوسة" مستحيلة هيكلياً.
٢. المنهجية الأساسية: الذكاء الاصطناعي كمُحسِّن ذكي للاستعلامات
٢.١ البنية المفاهيمية
تتكون المنهجية من ثلاث طبقات:

٢.٢ لماذا الأدوات بدلاً من التدريب؟
| المنهج | ماذا يفعل الذكاء الاصطناعي | المخاطر |
|---|
| التدريب المباشر | يُولِّد نصاً من أنماط مُتعلَّمة | هلوسة، أخطاء، اختلاق |
| Vector Retrieval | يجد تضمينات متشابهة دلالياً | يفقد العلاقات الصرفية |
| المُعزَّز بالأدوات (منهجنا) | يستدعي دوال بحث متخصصة | لا شيء — يُرجع النص المُفهرَس فقط |
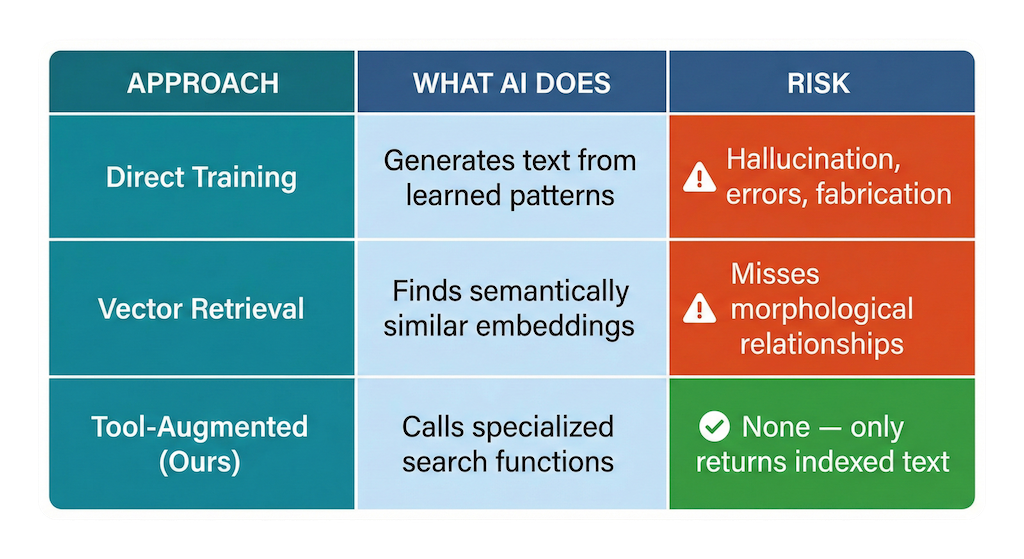
الرؤية الأساسية هي أن خبرة البحث أكثر قيمة من حفظ النص للقرآن. نريد أن يعرف الذكاء الاصطناعي كيف يجد الآيات، لا أن يتذكر الآيات.
٣. نظام الأدوات: منح الذكاء الاصطناعي خبرة البحث
٣.١ الفلسفة: أدوات متخصصة للمعرفة المتخصصة
مجال البحث القرآني له متطلبات محددة لا يملكها الذكاء الاصطناعي للأغراض العامة:
- الصرف العربي — الكلمات مشتقة من جذور ثلاثية بأنماط معقدة
- التصنيف الموضوعي — تصنيف علمي للآيات حسب الموضوع
- المواقع الدقيقة — الآيات الشهيرة لها عناوين محددة
- العد والإحصائيات — أسئلة "كم مرة؟" تتطلب إجابات دقيقة
نعالج هذه المتطلبات بتزويد الذكاء الاصطناعي بأدوات متخصصة:
٣.٢ الأداة الأولى: البحث الموضوعي (search_topics)
الغرض: إيجاد الآيات حسب التصنيف الموضوعي العلمي، وليس مجرد وجود الكلمة.
لماذا هي ضرورية: المستخدم الذي يسأل عن "الصبر في القرآن" يتوقع آيات صنفها العلماء تحت موضوع الصبر — وليس مجرد آيات تحتوي كلمة صبر.
كيف تعمل:
المستخدم: "آيات عن الصبر"
الذكاء الاصطناعي يستدعي: search_topics("الصبر")
النتيجة: فرع:"الصبر" — موضوع 'الصبر' موجود مع ٤٥ آية مُصنَّفة
الذكاء الاصطناعي يُرجع: آيات مُصنَّفة موضوعياً عن الصبر
التسلسل الموضوعي:
- فصل — الموضوعات الرئيسية مثل "أركان الإسلام"
- فرع — الموضوعات الفرعية مثل "الصبر"، "الصلاة"
- باب — القصص المحددة مثل "إبراهيم عليه السلام"
٣.٣ الأداة الثانية: التحقق من الكلمات (check_quran_word)
الغرض: التحقق من وجود كلمة في القرآن قبل البحث عنها.
لماذا هي ضرورية: قد يستخدم المستخدمون مصطلحات عربية حديثة لا تظهر في القرآن، أو يرتكبون أخطاء إملائية. يحتاج الذكاء الاصطناعي للتحقق من وجود الكلمة قبل بناء الاستعلامات.
كيف تعمل:
المستخدم: "آيات عن الذرية"
الذكاء الاصطناعي يستدعي: check_quran_word("ذرية")
النتيجة: "الكلمة موجودة. الصيغ: ذرية، ذريته، ذريتك، ذريتي، ذريتنا"
الآن يعرف الذكاء الاصطناعي الصيغ الدقيقة للبحث عنها.
٣.٤ الأداة الثالثة: تصحيح الإملاء (suggest_similar_words)
الغرض: التعامل مع الأخطاء الإملائية وأخطاء التحويل من الصوت للنص.
لماذا هي ضرورية: مدخلات المستخدم غالباً تأتي من التعرف الصوتي أو تحتوي أخطاء كتابية. يحتاج الذكاء الاصطناعي لإيجاد الكلمة القرآنية المقصودة.
كيف تعمل:
المستخدم يقول: "آيات عن الاخلاق المسمومه" (خطأ في التعرف الصوتي)
الذكاء الاصطناعي يتحقق: check_quran_word("مسمومه") ← غير موجودة
الذكاء الاصطناعي يستدعي: suggest_similar_words("مسمومه")
النتيجة: "كلمات مشابهة: مذمومة"
الذكاء الاصطناعي يفهم: المستخدم قصد "الأخلاق المذمومة"
٣.٥ الأداة الرابعة: عد الكلمات (count_word_matches)
الغرض: الإجابة على أسئلة "كم مرة؟" بدقة.
لماذا هي ضرورية: المستخدمون كثيراً ما يسألون أسئلة مثل "كم مرة ذُكر الصبر في القرآن؟" الذكاء الاصطناعي الذي يُخمِّن بناءً على أنماط التدريب سيُخطئ غالباً. هذه الأداة توفر أعداداً دقيقة.
كيف تعمل:
المستخدم: "كم مرة ذكرت الجنة في القرآن؟"
الذكاء الاصطناعي يستدعي: count_word_matches(">جنة") // بحث بالمادة
النتيجة:
- إجمالي التكرارات: ٨٧
- صيغ مختلفة: ٩
- في: ٨٤ آية
- الصيغ: الجنة (٥٦)، جنة (١٨)، جنتان (٣)، جنتين (٢)، وجنة (٢)...
الذكاء الاصطناعي يجيب بدقة: "الجنة ذكرت ٨٧ مرة في القرآن في ٨٤ آية"
٣.٦ الأداة الخامسة: اختبار الاستعلام (test_search)
الغرض: التحقق من أن الاستعلام يُرجع نتائج قبل إعطائه للمستخدم.
لماذا هي ضرورية: الاستعلامات المعقدة (خاصة مع منطق AND) قد تُرجع صفر نتائج. يجب على الذكاء الاصطناعي التحقق والتعديل قبل الإجابة.
كيف تعمل:
الذكاء الاصطناعي يبني: "الصبر و البلاء"
الذكاء الاصطناعي يستدعي: test_search("الصبر و البلاء")
النتيجة: "٠ نتائج" — الكلمات لا تظهر معاً
الذكاء الاصطناعي يُعدِّل: يستخدم البحث بالجذر ">>صبر و >>بلو"
الذكاء الاصطناعي يستدعي: test_search(">>صبر و >>بلو")
النتيجة: "١٥ نتيجة" — نجاح!
٣.٧ الأداة السادسة: التسليم النهائي (submit_query)
الغرض: إنهاء الاستعلام المُحسَّن مع الشرح.
كيف تعمل:
الذكاء الاصطناعي يستدعي: submit_query(
searchBy: 'فرع:"الصبر"',
sortBy: 'mushaf',
explain: 'الآيات المصنفة موضوعياً تحت باب الصبر والابتلاء'
)
الشرح يساعد المستخدمين على فهم لماذا أُرجعت هذه الآيات.
٤. الصرف العربي: تحدي نظام الجذور
٤.١ لماذا الصرف مهم
العربية مبنية على نظام جذور مختلف جوهرياً عن اللغات الهندوأوروبية. معظم الكلمات مشتقة من جذور ثلاثية (أنماط من ثلاثة أحرف ساكنة) تحمل المعنى الأساسي:
| الجذر | المعنى الأساسي | المشتقات |
|---|
| ص-ب-ر | الصبر | صَبَرَ، صَابِر، صَبُور، الصَّابِرِينَ |
| ك-ت-ب | الكتابة | كَتَبَ، كِتَاب، كَاتِب، مَكْتُوب |
| ع-ل-م | العلم | عَلِمَ، عَالِم، عِلْم، مَعْلُوم |
٤.٢ البحث بالمادة مقابل البحث بالجذر
طبقة البحث توفر مستويين من التوسع الصرفي:
البحث بالمادة (Lemma) (>كلمة) — يجد كل صيغ نفس الكلمة:
>نار ← نار، النار، ناراً
البحث بالجذر (Root) (>>كلمة) — يجد كل مشتقات الجذر:
>>صبر ← صَبَرَ، صَابِر، صَبُور، اصْطَبَرَ، الصَّابِرِين، تَصْبِرُوا...
٤.٣ متى نستخدم أيهما
يُعلَّم الذكاء الاصطناعي الاختيار بناءً على العلاقات الدلالية:
استخدم المادة (Lemma) عندما الجذر يتضمن معانٍ غير مرتبطة:
✓ >نار (النار فقط)
✗ >>نار (سيتضمن نُور = الضوء — معنى مختلف!)
استخدم الجذر (Root) عندما كل المشتقات تشترك في المعنى:
✓ >>صبر (كل الكلمات المتعلقة بالصبر)
✓ >>كتب (كل الكلمات المتعلقة بالكتابة)
٥. عملية استدلال الذكاء الاصطناعي: مثال كامل
لنتتبع كيف يتعامل الذكاء الاصطناعي مع استعلام معقد:
مثال: "آيات عن قصة سيدنا إبراهيم"
الخطوة ١: فهم النية
استدلال الذكاء الاصطناعي: "المستخدم يريد آيات عن قصة سيدنا إبراهيم.
هذا موضوع قصة/نبي، وليس بحثاً عن كلمة واحدة.
دعني أتحقق إن كان هناك موضوع مُصنَّف."
الخطوة ٢: البحث عن التصنيف الموضوعي
الذكاء الاصطناعي يستدعي: search_topics("إبراهيم")
النتيجة: باب:"إبراهيم عليه السلام" — ٨٣ آية مُصنَّفة
الخطوة ٣: التحقق من النتائج
الذكاء الاصطناعي يستدعي: test_search('باب:"إبراهيم عليه السلام"')
النتيجة: "٨٣ نتيجة. عينات: البقرة:١٢٤، البقرة:١٢٥، البقرة:١٢٦..."
الخطوة ٤: تسليم الاستعلام المُحسَّن
الذكاء الاصطناعي يستدعي: submit_query(
searchBy: 'باب:"إبراهيم عليه السلام"',
sortBy: 'mushaf',
explain: 'الآيات التي تتحدث عن قصة سيدنا إبراهيم عليه السلام'
)
لماذا هذا أفضل من التدريب المباشر:
- الذكاء الاصطناعي المُدرَّب قد يبحث عن كلمة "إبراهيم" ويفوت آيات تشير إليه دون ذكر اسمه
- البحث الموضوعي يُرجع اختيارات علمية مُنسَّقة تتضمن آيات السياق
- الذكاء الاصطناعي اكتشف الموضوع من خلال استدعاءات الأدوات، وليس من التدريب المحفوظ
مثال: "كم مرة ذكر موسى في القرآن أكثر من إبراهيم؟"
الخطوة ١: عد تكرارات موسى
الذكاء الاصطناعي يستدعي: count_word_matches(">>موسى")
النتيجة: ١٣٦ تكراراً في ١٣١ آية
الخطوة ٢: عد تكرارات إبراهيم
الذكاء الاصطناعي يستدعي: count_word_matches(">>إبراهيم")
النتيجة: ٦٩ تكراراً في ٦٣ آية
الخطوة ٣: تقديم إجابة مقارنة
الذكاء الاصطناعي يستدعي: submit_query(
searchBy: '>>موسى',
sortBy: 'mushaf',
explain: 'موسى ذكر في القرآن ١٣٦ مرة بينما إبراهيم ذكر ٦٩ مرة. موسى أكثر الأنبياء ذكراً'
)
لماذا هذا أفضل:
- الذكاء الاصطناعي المُدرَّب سيُقدِّر بناءً على الأنماط — غالباً بشكل خاطئ
- أداة العد توفر أرقاماً دقيقة من الفهرس
- المقارنة دقيقة رياضياً، وليست تخميناً
٦. التحليل المقارن: لماذا هذه المنهجية أفضل
٦.١ التدريب المباشر مقابل النهج المُعزَّز بالأدوات
| المعيار | تدريب الذكاء الاصطناعي المباشر | المُعزَّز بالأدوات (منهجنا) |
|---|
| دقة النص | قد يُهلوس أو يُخطئ الاقتباس | نص مُفهرَس دقيق فقط |
| التحليل الصرفي | مطابقة أنماط سطحية | توسع حقيقي بالجذر/المادة |
| البحث الموضوعي | لا يستطيع تعلم التصنيفات العلمية | موضوعات مُفهرَسة مُنسَّقة |
| عد الكلمات | تقديرات احتمالية | أعداد دقيقة |
| الأخطاء الإملائية | قد يفشل بصمت | تصحيح نشط عبر الأدوات |
| الشفافية | صندوق أسود | الاستعلام + الاستدلال مرئي |
| التحديثات | تتطلب إعادة تدريب كاملة | تحديث الفهرس فقط |
٦.٢ الـ Vector Retrieval مقابل النهج المُعزَّز بالأدوات
| المعيار | Vector Retrieval | المُعزَّز بالأدوات (منهجنا) |
|---|
| التغطية الصرفية | يعامل صيغ الجذر كمنفصلة | يتوسع بالجذر/المادة |
| التجميع الموضوعي | على أساس التشابه الدلالي | على أساس التصنيف العلمي |
| المطابقة الدقيقة | ضبابي بالتصميم | بحث دقيق بالحقول متاح |
| الاستعلامات المعقدة | دعم محدود للمنطق البولياني | AND/OR/NOT كامل |
| استعلامات العد | غير مدعوم | إحصائيات كلمات دقيقة |
٦.٣ ضمان عدم الهلوسة
الميزة الأكثر أهمية: الذكاء الاصطناعي لا يستطيع اختلاق نص قرآني.
في منهجيتنا:
- الذكاء الاصطناعي لا يُولِّد عربية قرآنية أبداً
- الذكاء الاصطناعي يبني استعلامات بحث فقط
- النتائج تأتي حصرياً من الفهرس المُوثَّق
- كل آية لها موقع مصدر قابل للتتبع
هذا ضمان هيكلي، وليس تحسيناً احتمالياً.
٧. التعامل مع أنواع الاستعلامات الخاصة
٧.١ استعلامات الآيات الشهيرة
غالباً ما يسأل المستخدمون عن آيات شهيرة باسمها، وليس محتواها:
| استعلام المستخدم | التحدي | الحل |
|---|
| "آية الكرسي" | هذا اسم، وليس كلمة للبحث | الذكاء الاصطناعي يعرف الموقع: ٢:٢٥٥ |
| "آية النور" | اسم آية شهيرة | الذكاء الاصطناعي يعرف الموقع: ٢٤:٣٥ |
| "آية الدين" | أطول آية في القرآن | الذكاء الاصطناعي يعرف الموقع: ٢:٢٨٢ |
System prompt يزود الذكاء الاصطناعي بهذه التعيينات، مما يسمح باسترجاع الموقع مباشرة.
٧.٢ المصطلحات الحديثة إلى المفردات القرآنية
قد يستخدم المستخدمون مصطلحات عربية حديثة لا تظهر في القرآن:
| المصطلح الحديث | المقابل القرآني |
|---|
| حجاب | جلباب، خُمُر (القرآن يستخدم هذه الكلمات) |
| إرهاب | لا يوجد مقابل مباشر — يحتاج بحثاً مفاهيمياً |
يُدرَّب الذكاء الاصطناعي على التعرف على هذه الفجوات وإما ترجمتها للمفردات القرآنية أو شرح أن المصطلح الدقيق لا يظهر.
٧.٣ استعلامات المعنى الإيجابي مقابل السلبي
بعض الاستعلامات تحتاج تعاملاً دقيقاً مع النفي:
المستخدم: "من يحبهم الله"
المنهج الخطأ: بحث ">يحب و الله"
المشكلة: يُرجع "لا يحب الله الظالمين" (الله لا يحب الظالمين)
المنهج الصحيح: ">يحب و الله وليس لا"
المعنى: "يحب AND الله EXCLUDE 'لا' (النفي)"
النتيجة: فقط الآيات الإيجابية عمن يحبهم الله
يُعلَّم الذكاء الاصطناعي اكتشاف النية الإيجابية/السلبية وبناء استعلامات استبعاد مناسبة.
٨. التعميم: تطبيق المنهجية على نصوص أخرى
٨.١ متطلبات البحث القرآني المُعزَّز بالأدوات
يمكن تطبيق هذه المنهجية على أي corpus حيث:
١. سلامة النص ذات أهمية قصوى — لا يُقبَل اختلاق
٢. يوجد تعقيد صرفي — أنظمة جذور، تصريفات
٣. يوجد تصنيف علمي — تنظيم موضوعي أو هيكلي
٤. تُحتاج إحصائيات دقيقة — عد، تحليل تكرار
٨.٢ تطبيقات محتملة
| الـ Corpus | التحدي الصرفي | نظام التصنيف |
|---|
| الحديث | الجذور العربية، سلاسل الرواية | الكتب، الأبواب، الرواة |
| التوراة | الجذور الثلاثية | الأسفار، الإصحاحات، الموضوعات |
| القوانين | المصطلحات التقنية | الأقسام، الفروع، المواضيع |
| الأدب الطبي | الجذور اللاتينية/اليونانية | التخصصات، الحالات، العلاجات |
٩. الخاتمة
قدمت هذه الورقة منهجية للبحث في القرآن بالذكاء الاصطناعي تختلف جوهرياً عن مناهج NLP التقليدية. مساهماتنا الرئيسية:
١. إعادة صياغة فلسفية: للقرآن، يجب أن يُحسِّن الذكاء الاصطناعي الاستعلامات، لا أن يُولِّد النص
٢. نظام أدوات عملي: ست أدوات متخصصة تغطي البحث الموضوعي، والتحليل الصرفي، وتصحيح الإملاء، وعد الكلمات، والتحقق من الاستعلامات، وتسليم النتائج
٣. بنية بدون هلوسة: ضمانات هيكلية أن الذكاء الاصطناعي لا يستطيع اختلاق نص قرآني
٤. قابلية التطبيق المُثبَتة: المنهجية تتعامل مع استعلامات معقدة تشمل الاستكشاف الموضوعي، وعد الكلمات، واستعلامات المقارنة، والبحث عن الآيات الشهيرة
الرؤية المركزية هي أن خبرة البحث أكثر قيمة من حفظ النص للقرآن. بتزويد الذكاء الاصطناعي بأدوات بحث متخصصة متصلة بفهرس مُوثَّق، نحقق سهولة تفاعل اللغة الطبيعية مع الحفاظ على الأمانة النصية المطلقة التي يتطلبها القرآن.
هذا النهج يحترم قدسية النص بضمان أن كل نتيجة هي استرجاع أمين من المصدر الأصلي. يصبح الذكاء الاصطناعي مرشداً خبيراً يساعد المستخدمين على التنقل في القرآن، وليس مُولِّداً يحاول إعادة إنتاجه.
المراجع
Chelli, A. et al. (2009-2024). "Alfanous: Quranic Search Engine." Open source project demonstrating specialized Quranic search.
Available at: https://github.com/Alfanous-team/alfanous
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Advances in Neural Information Processing Systems (NeurIPS 2020).
Available at: https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
Habash, N. (2010). "Introduction to Arabic Natural Language Processing." Synthesis Lectures on Human Language Technologies, Morgan & Claypool Publishers.
Available at: https://www.morganclaypool.com/doi/abs/10.2200/S00277ED1V01Y201008HLT010
Dukes, K. "The Quranic Arabic Corpus: Morphological Annotation." University of Leeds.
Available at: https://corpus.quran.com

