أشارككم في هذا الموضوع ملخص لورقة بحثية مرجعية حديثة ومهمة اطلعت عليها بعنوان مراجعة شاملة للذكاء الاصطناعي في الأبحاث القرآنية: الاتجاهات، والمنهجيات، والتحديات، والمسارات المستقبلية.
A comprehensive review of Artificial Intelligence in Qur’anic research: Trends, methods, challenges, and future directions.
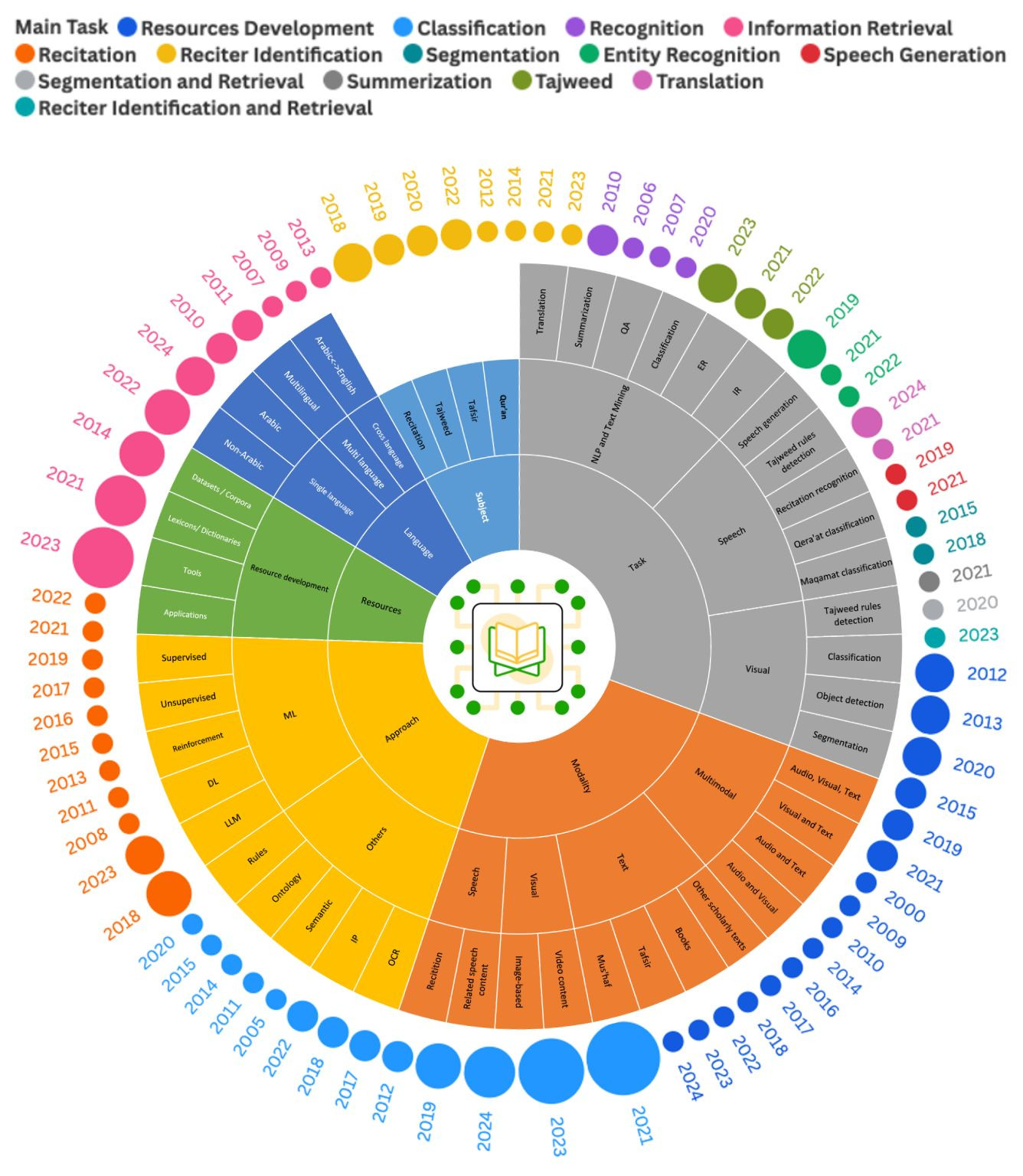
أعد هذه الورقة د. صدام العزاني Sadam Hussein Al-Azani من جامعة الملك فهد للبترول والمعادن بالتعاون مع د. شادي أبو ضلفة Shadi Abudalfa ، ود. حسين بن سما Hussein Samma.
تقدم الورقة تحليلاً نقدياً لـ 151 دراسة أساسية في هذا المجال لترسم خارطة طريق واضحة للمطورين والباحثين التقنيين، ولا تكتفي بسرد التقنيات المستخدمة بل تطرح إطارًا يساعد على تحقيق التوازن بين الابتكار التقني الحديث، وبين الصرامة الشرعية والأخلاقية التي يفرضها التعامل مع النص القرآني.
إليكم أبرز المحاور التي وردت في الورقة البحثية:
اتجاهات البحث والتطوير | Research Trends
رصدت الورقة التطور التاريخي لاستخدام الذكاء الاصطناعي في المجال القرآني وقسمتها إلى ثلاث حقب زمنية رئيسية:
المرحلة التأسيسية (2000-2011): هيمنت فيها الطرق الإحصائية (Statistical Methods) والأنظمة القائمة على القواعد (Rule-based Systems). شهدت هذه الفترة بدايات لتقنيات تعلم الآلة الكلاسيكية، مثل استخدام نماذج ماركوف المخفية (HMM) في التحليل الصوتي المبدئي، وخوارزمية آلة المتجهات الداعمة (SVM) في تصنيف النصوص.
المرحلة الانتقالية (2012-2017): شهدت ظهور مقاربات هجينة، حيث برزت تقنيات الأنطولوجيا (Ontologies) لتمثيل المعاني القرآنية هيكلياً، بالإضافة إلى تقنيات نمذجة المواضيع، كما بدأ استخدام التعلم العميق (Deep Learning) يظهر تدريجيًا.
حقبة الذكاء الاصطناعي الحديث (2018-الآن): تميزت بالاستخدام الواسع للتعلم العميق، والشبكات العصبية الالتفافية (CNN) والشبكار التكرارية (RNN). كما شهدت دخول هيكلية المحولات (Transformers) والنماذج اللغوية الضخمة (LLMs) مثل AraBERT و GPT-4، مع توجه نحو الذكاء الاصطناعي متعدد الوسائط (Multimodal AI) الذي يدمج النص والصوت والصورة.
الموارد والمصادر المعرفية | Knowledge Resources
استعرضت الورقة الجهود المبذولة في بناء مجموعات البيانات Datasets وأنطولوجيات Ontologies مع تقييم مدى إتاحتها للباحثين:
تطور الأنطولوجيات: تركزت الجهود المبكرة على بناء قواعد معرفية وأنطولوجيات تهتم بالجانب النحوي والصرفي، مثل البنك الشجري لتمثيل العلاقات النحوية والصرفية بين الكلمات القرآنية (QADT)، وصولاً إلى الأنطولوجيات الدلالية المتقدمة لتمثيل مفاهيم القرآن وتصنيفاته الموضوعية.
مجموعات البيانات (Datasets): تنوعت لتشمل مدونات نصية للإجابة على الأسئلة مثل (QRCD و AQQAC)، وقواعد بيانات صوتية لتقييم التلاوة مثل (Ar-DAD و Tarteel و QDAT)، بالإضافة إلى قواعد بيانات مرئية لاكتشاف أحكام التجويد ومخارج الحروف مثل (AQAND).
الفجوة الحالية: أظهرت الدراسة أن أغلب الموارد المتاحة تعاني من صغر حجمها، أو محدودية نطاقها، فضلاً عن أن العديد من قواعد البيانات المطورة داخلياً في الأبحاث غير متاحة للعامة، مما يعيق مبدأ قابلية التكرار (Reproducibility) ويحد من التطور التراكمي في هذا المجال.
المقاربات والمهام الرئيسية للذكاء الاصطناعي | Tasks & Modalities
حصرت الدراسة المجالات التي يعمل الذكاء الاصطناعي اليوم لخدمة القرآن الكريم وقسمت تطبيقات الذكاء الاصطناعي في الأبحاث القرآنية لعدة فئات بالاعتماد على نوع البيانات:
1. المقاربات المعتمدة على النصوص (Text-based Approaches)
- تصنيف النصوص القرآنية للتعرف على الآيات وتحديد أحكامها أو مواضيعها (مثل العقيدة، العبادات، والأخلاق).
- تطوير أنظمة الإجابة على الأسئلة (QA) واسترجاع المعلومات لتسهيل الوصول إلى الفتاوى أو استخراج التفسير المناسب للآيات.
- التعرف على الكيانات المسماة (NER) لتحديد أسماء الأشخاص، الأماكن، والأحداث داخل النص القرآني.
- التحليل الدلالي وتطوير الأنطولوجيات لفهم الروابط المعرفية بين الكلمات والآيات.
- الترجمة الآلية لمعاني القرآن، وتلخيص كتب التفسير لتسهيل قراءتها وفهمها.
2. المقاربات المعتمدة على الصوت (Speech-based Approaches)
- التعرف على التلاوة والتحقق من صحتها من خلال اكتشاف أخطاء التجويد أو أخطاء النطق (اللحن الجلي والخفي).
- تصنيف المقامات القرآنية واللكنات المختلفة.
- التعرف على هوية القارئ (Reciter Identification) من خلال تحليل البصمة الصوتية.
- أنظمة تحويل النص إلى كلام (TTS) لتوليد تلاوات قرآنية دقيقة.
3. المقاربات البصرية ومتعددة الوسائط (Visual & Multimodal Approaches)
- استخدام تقنيات الرؤية الحاسوبية للتعرف البصري على الحروف (OCR) ومعالجة المخطوطات القرآنية.
- اكتشاف واستخراج علامات وأحكام التجويد الملونة من صور المصحف.
- التعرف على لغة الإشارة والتعرف البصري على الكلام مثل قراءة الشفاه لتسهيل الوصول للمستخدمين من ذوي الاحتياجات الخاصة.
- الأنظمة متعددة الوسائط التي تدمج النص، الصوت، والصورة لتوفير بيئة تفاعلية شاملة لتعلم القرآن وتجويده.
التحديات والصعوبات | Challenges
يواجه المطورون في المجال القرآني تحديات فريدة لا تتواجد عادة في التطبيقات التقنية العادية وأبرزها:
- تحديات معالجة اللغة الطبيعية العربية Arabic NLP: بسبب التعقيد الصرفي للغة، وتعدد القراءات، إلى جانب اختلاف الرسم العثماني عن الإملاء المعاصر في قواعد الحذف والزيادة والوصل.
- ندرة البيانات المعيارية: فهناك نقص الموارد الموحدة وقواعد البيانات الكبيرة والمفتوحة المصدروالموثقة شرعياً لتدريب النماذج بكفاءة، حيث تعتمد أغلب الأنظمة على بيانات محلية ضيقة النطاق أو مقتصرة على سور وأحكام محددة.
- الاعتبارات الأخلاقية والدينية: فالتطبيقات العادية تتسامح مع هامش من الخطأ التقني، في حين يفرض النص القرآني وتفسيره دقة مطلقة ويجب على الخوارزميات التمييز بدقة بين اللحن الجلي الذي يغير المعنى واللحن الخفي، وتجنب الهلوسة في تفسير الآيات.
الحلول التقنية المقترحة | RAG كضرورة شرعية
أظهرت الورقة أن النماذج التوليدية العامة مثل ChatGPT تعاني من مشكلات خطيرة عند التعامل مع القرآن، أبرزها الهلوسة، الفهم السطحي للكلمات بعيدًا عن أسباب النزول، وعدم القدرة على توثيق المصادر، مما قد يؤدي إلى استنباطات مضللة.
لحل ذلك، توصي الورقة بتبني تقنية التوليد المعزز بالاسترجاع RAG كضرورة شرعية لتجنب هذه المخاطر عبر:
- بناء وتنسيق قواعد معرفية تضم أمهات كتب التفسير الموثوقة لتكون المرجع الأساسي.
- إجراء عملية استرجاع دقيق للنصوص من الأنطولوجيات قبل توليد أي إجابة.
- تطبيق التوليد المقيد (Constrained Generation)، بحيث تصاغ الإجابة حصراً من النصوص المسترجعة الموثوقة مع إرفاق استشهادات دقيقة للمصادر.
الاتجاهات المستقبلية | Future Directions
خلصت الدراسة لأهمية الانتقال للعمل المؤسسي، وتأسيس تحالفات استراتيجية متعددة التخصصات تجمع علماء الشريعة مع مطوري الذكاء الاصطناعي وخبراء اللغويات. وركزت في التوصيات على:
- تطوير أنظمة ذكاء اصطناعي تتجاوز المهام البسيطة لتشمل التعرف المتقدم على النطاق الكامل لأحكام التجويد والتحليلات التفسيرية العميقة.
- بناء قواعد بيانات ضخمة، موحدة، ومفتوحة المصدر، وتطوير معايير تقييم خاصة بالسياق القرآني.
- تخصيص نماذج الذكاء الاصطناعي التوليدي واللغوي (Generative AI & LLMs) لتكون حساسة ومتوافقة مع السياق الديني والفقهي.
- تأسيس مساحات للتعاون المشترك والدائم بين علماء الشريعة والدراسات الإسلامية من جهة وخبراء التقنية والذكاء الاصطناعي من جهة أخرى لضمان الموثوقية والدقة.
ختاماً أدعوكم لمطالعة المزيد من التفاصيل حول الورقة البحثية عبر هذا الرابط:
ومن خلال تجاربكم، ما أبرز التحديات التي تواجه المطورين عند التعامل مع أدوات ذكاء اصطناعي في تطبيقات تخدم القرآن الكريم وعلومه؟ وما السبيل لتوحيد الجهود في هذا المجال
شاركوني آراءكم في التعليقات.