أشارككم في هذا الموضوع خطوات بناء خط بيانات Data Pipeline لاستخراج النصوص القرآنية ضمن نظام متكامل لجمع بيانات القرآن الكريم من أحد المصادر الموثوقة عبر الإنترنت ومعالجتها ثم تصديرها بتنسيقات متعددة بحيث يمكن للمطورين استخدامها مباشرة في مشاريعهم.
أهمية تصميم Pipeline لمعالجة النصوص القرآنية
- جمع بيانات دقيقة ومحدثة: تم استخدام واجهة موثوقة لاستخراج النصوص وهي واجهة alquran.cloud/api.
- تنظيف وتوحيد النصوص: بإزالة التشكيل منها وتوحيد الحروف لتسهيل البحث والمطابقة النصية.
- توفير تنسيقات متعددة: مثل JSON وSQLite لتلبية احتياجات مشاريع مختلفة سواء للويب أو التطبيقات المحلية.
- التحقق من صحة البيانات: عن طريق التأكد من اكتمال أعداد السور والآيات التي تم استخراجها.
- مرونة وقابلية التوسع: إمكانية إضافة مصادر أو تنسيقات جديدة دون إعادة كتابة البنية الأساسية بالكامل.
مراحل تنفيذ خط البيانات
صممت خط البيانات ليجمع النصوص القرآنية من الواجهة البرمجية التي توفرها منصة Al Quran Cloud كما ذكرت سابقًا، ويمكن بالطبع استخدام أي واجهة أخرى موثوقة توفر المطلوب.
يتضمن خط البيانات عدة أصناف classes رئيسية تعمل بتسلسل سأوضحه تاليًا بإيجاز:
الإعداد والتكوين
تُخزَّن الإعدادات العامة ضمن صنف باسم Config لتسهل تعديلها وإدارتها، تشمل:
- عناوين الواجهة البرمجية API الأساسية
- المهل الزمنية وحدود الاتصال
- الأعداد الكلية المتوقعة للسور والآيات
- مسارات افتراضية لملفات الخرج الناتج
- كما يصنف التعداد RevelationType السور لمكية ومدنية كما يلي:
class Config:
API_BASE_URL = "https://api.alquran.cloud/v1"
TOTAL_SURAHS = 114
TOTAL_VERSES = 6236
DEFAULT_OUTPUT_DIR = "quran_output"
تسجيل الأحداث
يُفعَّل نظام تسجيل الأحداث Logging لتوثيق كل مرحلة من مراحل تنفيذ الـ Pipeline وتخزينها في ملف باسم quran_pipeline.log وهذا يفيد في تتبع الأداء ورصد الأخطاء وفهم التسلسل الزمني للعمل.
نماذج البيانات
يتم تعريف هياكل البيانات باستخدام مزخرف Decorator باسم dataclass@ لجعل البنية واضحة وآمنة. فكل آية تخزن ككائن VerseData يتضمن رقم السورة، ورقم الآية، والنص البسيط ونص الرسم العثماني. وباستخدام الخاصية frozen=True ستصبح هذه الكائنات غير قابلة للتعديل بعد إنشائها، مما يمنع أي تغييرات غير مقصودة عليها.
@dataclass(frozen=True)
class VerseData:
surah_number: int
verse_number: int
text_simple: str
text_uthmani: str = ""
تعريف استثناءات مخصصة
عرفت عدة استثناءات مخصصة Custom Exceptions لمعالجة الأخطاء:
- DataCollectionError: في حال فشل في جمع البيانات من الـ API مثل مشاكل الشبكة أو استجابات غير متوقعة.
- DataValidationError: عند وقوع خلل في التسلسل أو المحتوى بعد التحقق من البيانات كنقص في عدد الآيات.
- DataExportError: في حال حدوث مشكلة أثناء تصدير البيانات لأحد التنسيقات المطلوبة.
جمع البيانات
استخدمت الصنف QuranAPIClient مع المكتبة AIOHTTP لإرسال الطلبات بطريقة غير متزامنة Asynchronous لإرسال عدة طلبات للواجهة البرمجية في نفس الوقت دون انتظار انتهاء كل طلب على حدة لتسريع التنفيذ.
كما أضفت آلية إعادة المحاولة التدريجية Exponential Backoff فعند فشل الاتصال نحاول إرسال الطلب تلقائيًا وهذا يفيد في التعامل مع الأعطال المؤقتة في الشبكة أو الواجهة البرمجية.
معالجة النصوص
ينظف الصنف ArabicTextProcessor النصوص القرآنية ويوحدها لتسهيل البحث والمقارنة، وابرز الوظائف التي يقوم بها:
- توحيد الحروف: أي تحويل أشكال حرف الألف المختلفة أ، إ، آ إلى شكل موحد ا.
- تنظيف النصوص: إزالة الرموز غير العربية وغير المرغوبة والمسافات الزائدة.
- إزالة التشكيل: حذف الحركات لجعل النص أبسط وأكثر ملاءمة للمعالجة الآلية.
- دمج النصوص: جمع النصين البسيط وبالرسم العثماني في كائن VerseData يمثل كل آية.
التحقق من البيانات
يتولى الصنف QuranDataValidator فحص جودة البيانات والتأكد من اكتمالها وصحتها قبل اعتمادها، وتشمل مهامه:
- التأكد من وجود جميع سور القرآن وعددها 114 وجميع الآيات وعددها 6236، والتحقق من تسلسل الآيات داخل كل سورة بما يطابق الإحصائيات.
- التحقق من وجود نص لكل آية وخلوه من أحرف غير عربية، وضمان كون النصوص مرمزة ومقروءة بشكل سليم.
- التحقق من منطقية طول كل آية وأنه ضمن نطاق طبيعي (لا قصير جدًا ولا طويل على نحو غير مألوف) لكشف الأخطاء المحتملة في البيانات.
- توليد تقرير مفصل للنتائج يتضمن عدد السور والآيات المفحوصة، والمشكلات المكتشفة.
تصدير البيانات
يتولى الصنف QuranDataExporter إنشاء المخرجات ويولد بيانات القرآن الكريم بصيغ مختلفة تشمل تنسيق قاعدة بيانات SQLite وملفات جيسون JSON، كما يتولى الصنف إدارة البيانات الوصفية metadata والتأكد من سلامة التصدير، ويسجل الأحداث والإشعارات عبر أداة logger.
الربط والتنفيذ
يتولى الصنف QuranPipeline ربط وتنسيق جميع المراحل في سير عمل واحد عبر الدالة execute:
- جمع البيانات: استرجاع السور والآيات البسيطة والآيات بالرسم العثماني بشكل متزامن.
- معالجة النصوص: توحيد الحروف، إزالة التشكيل، ودمج النصوص في كائنات VerseData.
- التحقق من الصحة: التأكد من اكتمال السور والآيات وصحة النصوص.
- التصدير: إنشاء ملفات JSON شاملة ومبسطة وقاعدة بيانات SQLite وإحصاءات تحليلية.
- تسجيل الأحداث: توثيق كل خطوة وتحذير أو خطأ عبر logger.
كما تتولى الدالة main مهمة التنفيذ غير المتزامن لخط المعالجة باستخدام asyncio.run.
لتشغيل التطبيق نكتب:
python quran_pipeline.py
فتظهر لنا تباعًا كل مرحلة من مراحل التنفيذ في التيرمنال على النحو التالي:
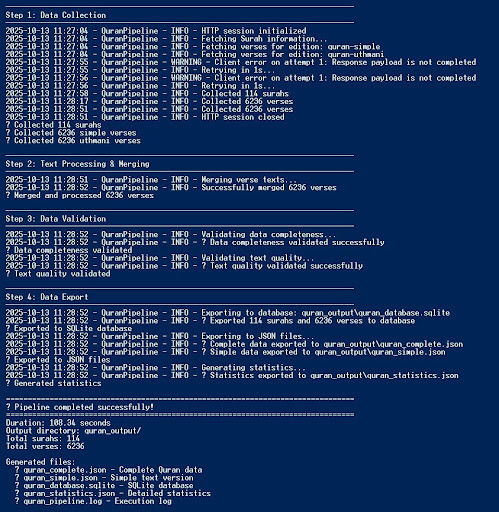
مخرجات خط البيانات
بعد تشغيل الكود البرمجي للـPipeline وانتهاء تنفيذ كافة المراحل المترابطة ينشأ مجلد باسم quran_output في مجلد المشروع يحتوي على المخرجات التالية:
- quran_complete.json: يشمل جميع النصوص (النص البسيط والنص بالرسم العثماني) وجميع المعلومات المتعلقة بالسور والآيات.
- quran_simple.json: يحتوي النص البسيط فقط ويناسب تطبيقات البحث السريع أو التطبيقات خفيفة الوزن.
- quran_database.sqlite: قاعدة بيانات SQLite منظمة تحوي السور والآيات لتسهيل الاستعلامات المحلية.
- quran_statistics.json: ملف إحصائي يتضمن ملخصات كعدد الكلمات والحروف وتصنيف السور مكية أم مدنية، ويفيد في دراسات تحليلية أو عرض معلومات إحصائية عامة عن القرآن الكريم.
- quran_pipeline.log: سجل كامل لسير العمل يحتوي على الرسائل المهمة والتحذيرات والأخطاء.
الكود البرمجي للمشروع
وفرت الكود الكامل للمشروع على مستودع جيتهب quran_pipeline. أرحب بالاطلاع عليه والمساهمة فيه بالتنبيه لأية أخطاء أو إضافة مصادر جديدة كالتفاسير والترجمات والبيانات الصوتية وغيرها من المصادر القرآنية، أو توفير تنسيقات تصدير أخرى يحتاجها المطورون مثل XML، CSV.
كانت هذه خلاصة تجربتي في بناء Pipeline لمعالجة البيانات القرآنية، أرجو أن تكون نقطة انطلاق لتطوير خط بيانات أكثر تطورًا وشمولية.
أود سماع تجاربكم وآرائكم، هل سبق أن كان لكم تجارب مشابهة في معالجة البيانات أو بناء Pipelines مشابهة، وما الأفكار التي تقترحونها لتطوير هذه الفكرة؟