المقدمة
يمثل البحث في القرآن الكريم تحديات فريدة لا تظهر في اللغة الإنجليزية أو معظم اللغات الأخرى. اللغة العربية لغة غنية اشتقاقياً؛ إذ يمكن لجذر واحد أن ينتج عشرات الكلمات المرتبطة بالمعنى نفسه، كما تتغير الكلمة الواحدة بتغير السياق، الزمن، أو الصيغة. لهذا السبب، يفشل البحث النصي التقليدي عندما يحاول المستخدم الوصول إلى المعنى الكامل بدل التطابق الحرفي فقط.
في هذا التحديث، قمت بتطوير محرك البحث في تطبيق Open Mushaf مفتوح المصدر ليكون أكثر ذكاءً وعمقاً، مع دعم البحث حسب:
- النص المباشر داخل الآية
- بحث تقريبي يلتقط الأخطاء الإملائية والاختلافات البسيطة
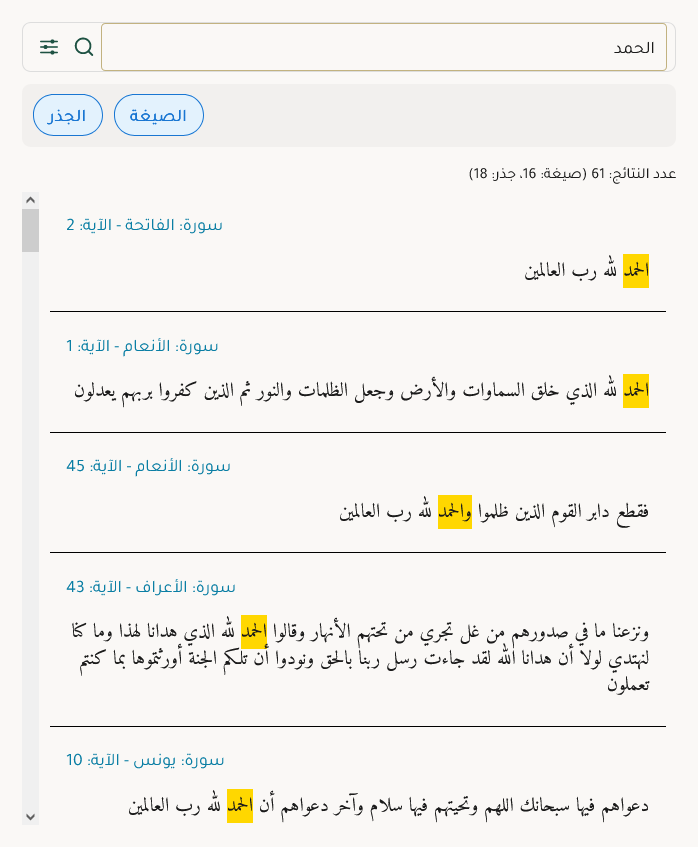
- صيغة الكلمة بغض النظر عن تصريفها
- الجذر اللغوي للكلمة
والأهم من ذلك:
جميع عمليات البحث تعمل بالكامل دون اتصال بالإنترنت، دون خوادم، دون API، ودون أي معالجة سحابية ولا ذكاء اصطناعي.
في هذا المقال، أشرح كيف تم بناء هذا المحرك خطوة بخطوة، بدءاً من البيانات اللغوية، مروراً بهياكل التخزين والخوارزميات، وصولاً إلى تنفيذ البحث والأداء داخل تطبيق React Native.
🔗 التطبيق مفتوح المصدر:
https://github.com/adelpro/open-mushaf-native
فهم علم الصرف العربي
قبل الغوص في التطبيق التقني، دعونا نفهم ما يجعل اللغة العربية فريدة.
نظام الجذور (الجذر)
الكلمات العربية مبنية من جذور ثلاثية (عادة 3 حروف صامتة) تحمل معنى دلالياً أساسياً. على سبيل المثال، الجذر ك-ت-ب (K-T-B) يتعلق بـ "الكتابة":
الجذر: كتب (K-T-B)
├── كَتَبَ (kataba) - كتب (هو)
├── يَكْتُبُ (yaktubu) - يكتب (هو)
├── كِتَاب (kitaab) - كتاب
├── كَاتِب (kaatib) - كاتب
├── مَكْتُوب (maktuub) - مكتوب
├── مَكْتَبَة (maktaba) - مكتبة
└── كُتُب (kutub) - كتب (جمع)
الصيغة
الصيغة هي الشكل القاموسي للكلمة.
في اللغة العربية:
جميع التصريفات والإعرابات تعود إلى صيغتها الأساسية:
الصيغة: كَتَبَ (kataba - "كتب")
├── كَتَبَ - كتب (هو)
├── كَتَبْتُ - كتبت (أنا)
├── كَتَبْنَا - كتبنا (نحن)
├── يَكْتُبُ - يكتب (هو)
├── تَكْتُبُ - تكتب (أنت/هي)
└── اكْتُبْ - اكتب! (أمر)
لماذا هذا مهم للبحث
عندما يبحث المستخدم عن "كتب"، فمن المحتمل أنه يريد العثور على:
- جميع الآيات التي يأمر الله فيها الناس بالكتابة
- جميع الآيات التي تذكر الكتب
البحث النصي البسيط سيفوت معظم هذه النتائج. هنا يصبح البحث الصرفي ضرورياً.
التحدي
بناء هذه الميزة تطلب حل عدة مشاكل:
1. الحصول على البيانات
احتجنا إلى بيانات صرفية لكلمات القرآن الكريم، بما في ذلك:
- الصيغة لكل كلمة
- الجذر لكل كلمة
- ربط دقيق بين أشكال الكلمات المختلفة
2. الأداء
- البحث في آلاف الكلمات في النص القرآني في الوقت الفعلي
- دعم أوضاع بحث متعددة في وقت واحد
- الحفاظ على تفاعلات واجهة المستخدم السلسة
- توفير كل هذا دون اتصال بالانترنت ودون الحاجة لاستعمال الذكاء الاصطناعي
3. الدقة
- معالجة تطبيع النص العربي (التشكيل، أشكال الهمزة)
- التعامل مع علم الصرف في اللغة العربية
- توفير نتائج ذات صلة مرتبة حسب الأهمية
4. تجربة المستخدم
- جعل الميزات اللغوية المعقدة متاحة للمستخدمين غير التقنيين
- توفير ملاحظات بصرية لأنواع التطابق المختلفة
- الموازنة بين القوة والبساطة وسرعة الآداء
نظرة عامة على البنية
يتكون حلنا من أربع طبقات رئيسية:
طبقة واجهة المستخدم
خوارزمية البحث (useQuranSearch) │
معالجة الاستعلام والتطبيع
تنسيق البحث متعدد الأوضاع
خوارزمية ترتيب النتائج حسب الأهمية
أدوات البحث searchutils.ts
طبقة البيانات (JSON)
هياكل البيانات
1. خريطة الكلمات (word-map.json)
تربط الكلمات العربية المطبعة بخصائصها اللغوية:
{
"كتب": {
"lemma": "كَتَبَ",
"root": "كتب"
},
"يكتب": {
"lemma": "كَتَبَ",
"root": "كتب"
},
"كتاب": {
"lemma": "كِتَاب",
"root": "كتب"
}
}
الحجم: 15,000 إدخال كلمة فريدة
الغرض: الصيغة/الجذر
2. بيانات الصرف (quran-morphology.json)
تخزن البيانات اللغوية لكل آية:
[
{
"gid": 1,
"lemmas": ["بِسْم", "اللَّه", "رَحْمَن", "رَحِيم"],
"roots": ["سمو", "اله", "رحم", "رحم"]
},
{
"gid": 2,
"lemmas": ["حَمْد", "اللَّه", "رَبّ", "عَالَم"],
"roots": ["حمد", "اله", "ربب", "علم"]
}
]
الحجم: 6,236 إدخال (واحد لكل آية)
الغرض: بحث سريع عن جميع الصيغ/الجذور في الآية
خوارزمية البحث
المرحلة 1: تطبيع الاستعلام
النص العربي يتطلب تعاملا خاصاً:
const normalizeArabic = (text: string): string => {
return text
.replace(/[أإآ]/g, 'ا') // تطبيع أشكال الألف
.replace(/[ىي]/g, 'ي') // تطبيع أشكال الياء
.replace(/ة/g, 'ه') // تطبيع التاء المربوطة
.replace(/[ًٌٍَُِّْ]/g, ''); // إزالة التشكيل
};
const cleanArabicQuery = (query: string): string => {
// الاحتفاظ بالحروف العربية والمسافات فقط
return normalizeArabic(query.replace(/[^\u0600-\u06FF\s]+/g, '').trim());
};
لماذا هذا مهم: قد يكتب المستخدمون "كتاب" لكن القرآن يحتوي على "كِتَابٌ" (مع التشكيل). التطبيع يضمن التطابق.
المرحلة 2: البحث متعدد الأوضاع
نقوم بتشغيل ما يصل إلى ثلاثة عمليات بحث في وقت واحد:
// 1. البحث النصي البسيط (يعمل دائماً)
const simpleMatches = simpleSearch(quranData, cleanQuery, 'standard').slice(
0,
MAX_RESULTS,
);
// 2. بحث الصيغة (إذا كان مفعلاً)
const lemmaMatches = advancedOptions.lemma
? performAdvancedLinguisticSearch(
cleanQuery,
quranData,
{ lemma: true, root: false },
fuseInstance,
).slice(0, MAX_RESULTS)
: [];
// 3. بحث الجذر (إذا كان مفعلاً)
const rootMatches = advancedOptions.root
? performAdvancedLinguisticSearch(
cleanQuery,
quranData,
{ lemma: false, root: true },
fuseInstance,
).slice(0, MAX_RESULTS)
: [];
// دمج جميع النتائج
const allMatches = [...simpleMatches, ...lemmaMatches, ...rootMatches];
المرحلة 3: البحث اللغوي المتقدم
هذه هي الخوارزمية الأساسية:
export const performAdvancedLinguisticSearch = (
query: string,
quranData: QuranText[],
options: AdvancedOptions,
fuseInstance: Fuse<QuranText>,
): QuranText[] => {
const cleanQuery = cleanArabicQuery(query);
if (!cleanQuery) return [];
// الخطوة 1: البحث عن الكلمة في خريطة الكلمات
const wordMap = wordMapJSON as WordMap;
const entry = wordMap[cleanQuery];
// إذا لم تكن الكلمة في الخريطة، العودة إلى البحث الضبابي
if (!entry) {
return fuseInstance.search(cleanQuery).map((r) => r.item);
}
const { lemma: targetLemma, root: targetRoot = '' } = entry;
const matchingGids = new Set<number>();
// الخطوة 2: البحث بالصيغة
if (options.lemma && targetLemma) {
for (const verse of quranData) {
const morph = getMorph(verse.gid);
if (morph?.lemmas.includes(targetLemma)) {
matchingGids.add(verse.gid);
}
}
}
// الخطوة 3: البحث بالجذر
if (options.root && targetRoot) {
for (const verse of quranData) {
const morph = getMorph(verse.gid);
if (morph?.roots.includes(targetRoot)) {
matchingGids.add(verse.gid);
}
}
}
// الخطوة 4: تحويل المعرفات إلى آيات
if (matchingGids.size > 0) {
const gidToVerse = new Map(quranData.map((v) => [v.gid, v]));
return Array.from(matchingGids).map((gid) => gidToVerse.get(gid)!);
}
// العودة إلى البحث الضبابي
return fuseInstance.search(cleanQuery).map((r) => r.item);
};
التعقيد الزمني: عدد الآيات (6,236)
التعقيد المكاني: عدد الآيات المطابقة
المرحلة 4: التسجيل والترتيب
كل نتيجة تحصل على درجة ملاءمة:
const computeScore = (
verse: QuranText,
cleanQuery: string,
mapEntry: { lemma?: string; root?: string } | undefined,
): ScoredQuranText => {
let score = 0;
let matchType: MatchType = 'none';
// التطابقات النصية الدقيقة: 3 نقاط لكل منها
const textMatches = getPositiveTokens(
verse,
'text',
undefined,
undefined,
cleanQuery,
);
if (textMatches.length > 0) {
score += textMatches.length * 3;
matchType = 'exact';
}
// تطابقات الصيغة: نقطتان لكل منها
if (advancedOptions.lemma && mapEntry?.lemma) {
const lemmaMatches = getPositiveTokens(
verse,
'lemma',
mapEntry.lemma,
undefined,
cleanQuery,
);
if (lemmaMatches.length > 0) {
score += lemmaMatches.length * 2;
if (matchType !== 'exact') matchType = 'lemma';
}
}
// تطابقات الجذر: نقطة واحدة لكل منها
if (advancedOptions.root && mapEntry?.root) {
const rootMatches = getPositiveTokens(
verse,
'root',
undefined,
mapEntry.root,
cleanQuery,
);
if (rootMatches.length > 0) {
score += rootMatches.length;
if (matchType !== 'exact' && matchType !== 'lemma') {
matchType = 'root';
}
}
}
return { ...verse, matchScore: score, matchType };
};
استراتيجية التسجيل:
التطابقات الدقيقة هي الأكثر قيمة (3 نقاط)
تطابقات الصيغة ذات قيمة متوسطة (نقطتان)
تطابقات الجذر الأقل قيمة لكنها لا تزال ذات صلة (نقطة واحدة)
يتم ترتيب النتائج حسب الدرجة بترتيب تنازلي.
المرحلة 5: إزالة التكرار
نظراً لأن الآية قد تتطابق في أوضاع متعددة، نقوم بإزالة التكرار:
const processSearchResults = (results: QuranText[], cleanQuery: string) => {
const gidSet = new Set<number>();
const combined: ScoredQuranText[] = [];
for (const v of results) {
if (!gidSet.has(v.gid)) {
gidSet.add(v.gid);
const mapEntry = wordMap[cleanQuery];
combined.push(computeScore(v, cleanQuery, mapEntry));
}
}
// الترتيب حسب الدرجة (الأعلى أولاً)
combined.sort((a, b) => b.matchScore - a.matchScore);
return combined;
};
تطبيق React Native
مكونات واجهة المستخدم
1. حقل البحث مع تصفية عربية
<ThemedTextInput
variant="outlined"
style={styles.searchInput}
placeholder="البحث..."
value={inputText}
onChangeText={(text) => {
// تصفية الحروف العربية فقط
const arabicOnly = text.replace(/[^\u0621-\u064A\s]/g, '');
setInputText(arabicOnly);
handleSearch(arabicOnly);
}}
/>
الميزة الرئيسية: تصفية تلقائية للأحرف غير العربية، مما يمنع عمليات البحث غير الصالحة.
2. تبديل الخيارات المتقدمة
const [advancedOptions, setAdvancedOptions] = useState({
lemma: false,
root: false,
});
const toggleOption = (option: keyof typeof advancedOptions) => {
setAdvancedOptions((prev) => ({
...prev,
[option]: !prev[option]
}));
};
// أزرار واجهة المستخدم
<Pressable
style={[
styles.optionButton,
advancedOptions.lemma && styles.optionActive,
]}
onPress={() => toggleOption('lemma')}
>
<ThemedText
style={advancedOptions.lemma ? styles.optionActiveText : undefined}
>
الصيغة
</ThemedText>
</Pressable>
الملاحظات البصرية: يتم تمييز الخيارات النشطة بخلفية زرقاء وحدود.
3. عداد النتائج
const selectedLabels: string[] = [];
if (advancedOptions.lemma) {
selectedLabels.push(`صيغة: ${counts.lemma}`);
}
if (advancedOptions.root) {
selectedLabels.push(`جذر: ${counts.root}`);
}
const counterText =
query.trim() === ''
? ''
: selectedLabels.length > 0
? `عدد النتائج: ${counts.total} (${selectedLabels.join('، ')})`
: `عدد النتائج: ${counts.total} (نص)`;
مثال على الإخراج: عدد النتائج: 45 (صيغة: 30، جذر: 15)
4. التمييز بالألوان
<HighlightText
text={item.standard}
tokens={directTokens} // أزرق - تطابقات دقيقة
relatedWords={relatedTokens} // أخضر - تطابقات صيغة/جذر
fuzzyWords={fuzzyTokens} // أصفر - تطابقات ضبابية
color={directColor}
relatedColor={relatedColor}
fuzzyColor={fuzzyColor}
style={{ fontSize: 18 }}
/>
التسلسل الهرمي البصري:
🔵 أزرق: تطابقات نصية مباشرة (الأكثر صلة)
🟢 أخضر: تطابقات صيغة/جذر (ذات صلة)
🟡 أصفر: تطابقات ضبابية (الأقل صلة)
Hook مخصص: useQuranSearch
قمنا بتغليف جميع منطق البحث في خطاف مخصص:
export default function useQuranSearch({
quranData,
morphologyData,
wordMap,
query,
advancedOptions,
fuseInstance,
}: UseQuranSearchProps) {
const [filteredResults, setFilteredResults] = useState<QuranText[]>([]);
const [counts, setCounts] = useState<Counts>({
simple: 0,
lemma: 0,
root: 0,
total: 0,
});
// منطق البحث في useEffect
useEffect(() => {
// ... تطبيق البحث
}, [query, quranData, fuseInstance, advancedOptions]);
return { filteredResults, counts, getPositiveTokens };
}
الفوائد:
✅ فصل الاهتمامات
✅ قابل لإعادة الاستخدام عبر المكونات
✅ إعادة بحث تلقائية عند تغيير التبعيات
✅ كود مفصول عن واجهة المستخدم
تحسينات الأداء
1. تأخير الإدخال (Debouncing)
const useDebounce = (callback: Function, delay: number) => {
const timeoutRef = useRef<NodeJS.Timeout>();
return useCallback(
(...args: any[]) => {
if (timeoutRef.current) {
clearTimeout(timeoutRef.current);
}
timeoutRef.current = setTimeout(() => {
callback(...args);
}, delay);
},
[callback, delay],
);
};
// الاستخدام
const handleSearch = useDebounce((text: string) => setQuery(text), 200);
التأثير: يقلل استدعاءات البحث من 10/ثانية إلى 5/ثانية أثناء الكتابة.
2. تحديد النتائج
const MAX_RESULTS = 500;
const simpleMatches = simpleSearch(quranData, cleanQuery, 'standard').slice(
0,
MAX_RESULTS,
);
المنطق:
تجربة المستخدم
مقاييس أداء البحث
متوسط وقت البحث: 50-150 مللي ثانية
**تأخير Debounce **200 مللي ثانية
الحد الأقصى للنتائج لكل وضع: 500
معدل إطارات واجهة المستخدم: 60 إطار في الثانية (محافظ عليه)
حجم البيانات : 2 ميجابايت (صرف + خريطة كلمات)
سيناريوهات بحث مثالية
السيناريو 1: العثور على جميع الآيات المتعلقة بالصلاة
الاستعلام: "صلى"
الأوضاع: الصيغة + الجذر مفعلان
النتائج:
قيمة المستخدم: رؤية شاملة للصلاة في القرآن.
السيناريو 2: دراسة مفهوم "العلم"
الاستعلام: "علم"
الأوضاع: الجذر مفعل
النتائج:
قيمة المستخدم: دراسة موضوعية للعلم في الإسلام.
الدروس المستفادة
1. جودة البيانات أمر بالغ الأهمية
استخدمنا بيانات صرفية مولدة تلقائياً ،محققة وعالية الجودة من Quranic Corpus.
3. بساطة واجهة المستخدم تخفي التعقيد
واجهة المستخدم تعتمد على أزرار تبديل بسيطة فقط.
4. تطبيع النص العربي صعب
واجهنا حالات استثنائية مثل:
الدرس المستفاد: استخدم مكتبات تطبيع مجربة عندما يكون ذلك ممكناً.


